В большинстве случаев поисковые боты начинают свою работу на сайте с файла robots.txt. Подобно дорожному знаку, он указывает, куда боты могут ходить на вашем сайте, а куда им ходить не следует. Так что если этот файл настроен неправильно, ранжирование вашего сайта в поисковиках может пойти не по плану. Чтобы этого не произошло, в этой статье рассмотрим, как работает robots.txt для WordPress и как настроить robots.txt WordPress-сайта.

Эта статья — свободный и дополненный перевод материала WordPress Robots.txt Guide: What It Is and How to Use It, который вышел в блоге Kinsta 🔗
Что такое WordPress-файл robots.txt
Прежде чем будем говорить о файле robots.txt WordPress, давайте определим, что такое «робот» в этом случае.
🔎 Роботы — это любой тип ботов, посещающих сайты в интернете. Наиболее распространенным примером будут поисковые роботы. Эти боты «ползают» по интернету, чтобы помочь поисковым системам вроде Google индексировать и ранжировать миллиарды страниц в сети.
Так что боты — это, в общем-то, хорошо для интернета. Или, по крайней мере, нужно. Но это не обязательно означает, что вы или другие владельцы сайтов хотите, чтобы боты бегали беспрепятственно.
Желание контролировать, как веб-роботы взаимодействуют с сайтами, привело к изобретению файла robots.txt. Robots.txt позволяет регулировать то, как «послушные» боты взаимодействуют с вашим сайтом. С его помощью вы можете полностью заблокировать ботов, ограничить их доступ к определенным частям вашего сайта и так далее.
Однако слово «послушные» тут играет важную роль. Robots.txt не может заставить бота следовать своим директивам. Вредоносные боты могут и будут игнорировать файл robots.txt. Кроме того, даже уважаемые организации игнорируют некоторые команды, которые можно указать в robots.txt.
К примеру, Google проигнорирует любые правила относительно частоты посещения сайта его поисковыми роботами, которые вы добавите к robots.txt. Вы можете настроить скорость, с которой Google сканирует ваш сайт, на странице настроек скорости сканирования для вашего сайта в Google Search Console.
Так что, если у вас много проблем с ботами, кроме robots.txt вам стоит использовать такие решения, как Cloudflare и Sucuri. Они могут защитить ваш сайт как от недобросовестных ботов, так и от различных атак, проверяя и фильтруя трафик, поступающий на ваш сайт.
🔗 Руководство по настройке Cloudflare
Но если у вас нет хлопот с ботами и вы просто хотите базово настроить доступ к сайту — продолжайте читать, эта статья ответит на ваши вопросы.
Когда стоит использовать файл robots.txt
Для большинства владельцев сайтов у хорошо структурированного файла robots.txt есть два основных преимущества:
- Поисковые системы быстрее обходят ваш сайт, не тратя время на страницы, которые вы не хотите, чтобы находили. Это помогает ботам сосредоточиться на том, что вам важно.
- Вы экономите ресурсы сервера, заблокировав нежелательных ботов, которые напрасно используют его мощности.
Также учитывайте, что robots.txt не является надежным способом контролировать, какие страницы индексируются поисковыми системами. Если ваша основная цель — не допустить, чтобы определенные страницы попали в результаты поиска, правильным подходом будет использовать правило noindex или защитить страницу паролем.
Это связано с тем, что файл robots.txt не запрещает поисковым системам индексировать содержимое — он только запрещает им сканировать его. Сам Google предупреждает, что если внешний сайт или другая страница вашего сайта ссылается на страницу, которую вы исключили из индекса с помощью файла robots.txt, Google все равно может проиндексировать эту страницу.
Джон Мюллер, аналитик Google Webmaster Analyst, также подтвердил, что если на странице есть ссылка, даже если она заблокирована файлом robots.txt, она все равно может быть проиндексирована. Ниже мы приводим, что он говорил на форуме Webmaster Central:
«Здесь следует помнить, что если эти страницы заблокированы robots.txt, то теоретически может произойти так, что кто-то случайно ссылается на одну из этих страниц. И если это произойдет, мы можем проиндексировать этот URL-адрес без какого-либо контента, потому что тот заблокирован файлом robots.txt. Таким образом, мы не будем знать, что вы не хотите, чтобы эти страницы были проиндексированы.
Если же они не заблокированы файлом robots.txt, вы можете поставить правило noindex на этих страницах. И если кто-то разместит на них ссылку, а мы перейдем по этой ссылке и подумаем, что здесь есть что-то полезное, то будем знать, что эти страницы не нужно индексировать, и сможем просто пропустить их полностью.
Поэтому, если на страницах есть что-то, что вы не хотите, чтобы было проиндексировано, не закрывайте их через robots.txt, а используйте noindex.»
Нужен ли мне файл robots.txt
Вам не обязательно иметь файл robots.txt на вашем сайте. Если вы не против того, что все боты могут свободно сканировать все ваши страницы, вы можете не добавлять его, поскольку у вас нет никаких реальных инструкций для роботов.
В некоторых случаях вы даже не сможете добавить файл robots.txt из-за ограничений CMS, которую вы используете. Это не страшно, ведь существуют другие способы указать ботам, как сканировать ваши страницы, не используя файл robots.txt.
Какой код статуса HTTP должен возвращаться для файла robots.txt
Файл robots.txt должен возвращать код статуса HTTP 200 OK, чтобы поисковые роботы могли получить к нему доступ.
🔗 Что такое коды состояния HTTP и как их проверять
Если у вас возникли проблемы с индексацией страниц поисковыми системами, следует дважды проверить код статуса, который возвращается для вашего файла robots.txt. Любой другой код статуса, кроме 200, может помешать роботам получить доступ к вашему сайту.
Некоторые владельцы сайтов сообщали, что их страницы были удалены из индекса из-за того, что файл robots.txt возвращал статус, отличный от 200. Владелец веб-сайта спросил о проблеме индексации в Google SEO Office Hours в марте 2022 года, и Джон Мюллер объяснил, что файл robots.txt должен возвращать либо статус 200, если он присутствует, либо статус 4XX, если файл не существует. В этом случае возвращалась внутренняя ошибка сервера 500, что, по словам Мюллера, могло привести к тому, что Googlebot исключил сайт из индексации.
То же можно увидеть в этом твите, где владелец сайта сообщил, что весь его сайт был деиндексирован из-за того, что файл robots.txt возвращал ошибку 500.
Можно ли использовать метатег robots вместо файла robots.txt
Нет. Метатег robots позволяет вам контролировать, какие страницы индексируются, а файл robots.txt позволяет контролировать, какие страницы сканируются. Боты должны сначала просканировать страницы, чтобы увидеть правила в них. Поэтому не следует одновременно использовать правила disallow и noindex, поскольку noindex не будет принят во внимание.
Если ваша цель исключить страницу из поисковых систем, директива noindex обычно является лучшим вариантом.
Статья по теме:

Как найти robots.txt на сайте
Обычно WordPress-сайт «из коробки» не имеет физического файла robots.txt, который вы могли бы редактировать, однако движок сам создает виртуальный вариант с набором базовых правил. Также многие SEO-плагины или плагины для управления сайтом могут создавать стандартный robots.txt для WordPress автоматически, как часть своего функционала. Поэтому стоит для начала проверить, есть ли у вас этот файл.
Где находится файл robots.txt:
Файл robots.txt находится в корне вашего сайта, чтобы его увидеть (если он у вас есть), добавьте /robots.txt после вашего домена. К примеру, https:/hostiq.ua/robots.txt.
Если по ссылке https://your-domain/robots.txt вы видите записи, но в корневом каталоге вашего сайта на хостинге файла с названием «robots.txt» нет — у вас есть только виртуальный robots.txt.
Чтобы отредактировать записи или добавить новые, читайте наш следующий раздел.
Как создать и редактировать файл robots.txt в WordPress
Перед вами пример robots.txt для WordPress, который генерирует сам движок.
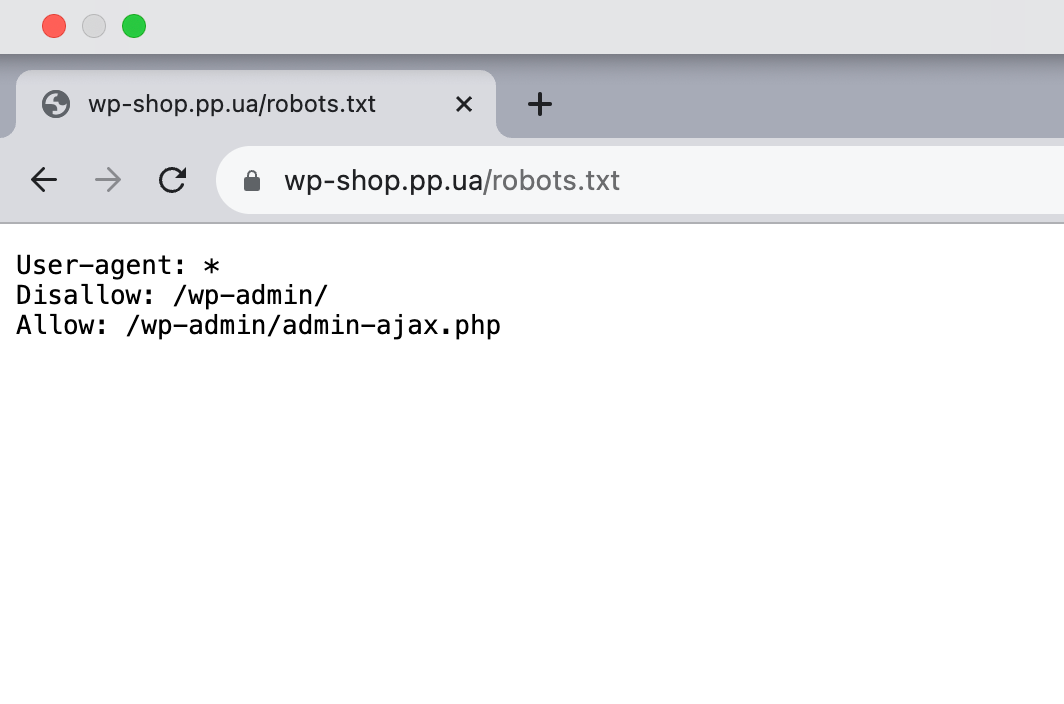
В нем всего три строчки со стандартными инструкциями для всех роботов: проходить мимо админпанели WordPress, то есть каталога /wp-admin/, но заходить в файл /wp-admin/admin-ajax.php.
Как мы говорили в предыдущей главе, стандартный robots.txt для WordPress является виртуальным, вы не можете его редактировать. Если вы хотите отредактировать файл robots.txt, вы должны создать физический файл на вашем сервере, с которым вы сможете работать при необходимости.
Вот три простых способа сделать это:
- создать и редактировать файл robots.txt в WordPress с помощью плагина Yoast SEO;
- создать и редактировать файл robots.txt с помощью плагина All in One SEO;
- создать и редактировать файл robots.txt через FTP.
Разберемся в каждом из них поподробнее.
Как создать файл robots.txt для WordPress с помощью Yoast SEO
Если вы используете популярный плагин Yoast SEO, вы можете создать и отредактировать файл robots.txt прямо из интерфейса Yoast. Для этого перейдите в меню слева в раздел Yoast SEO → Tools и нажмите File editor.
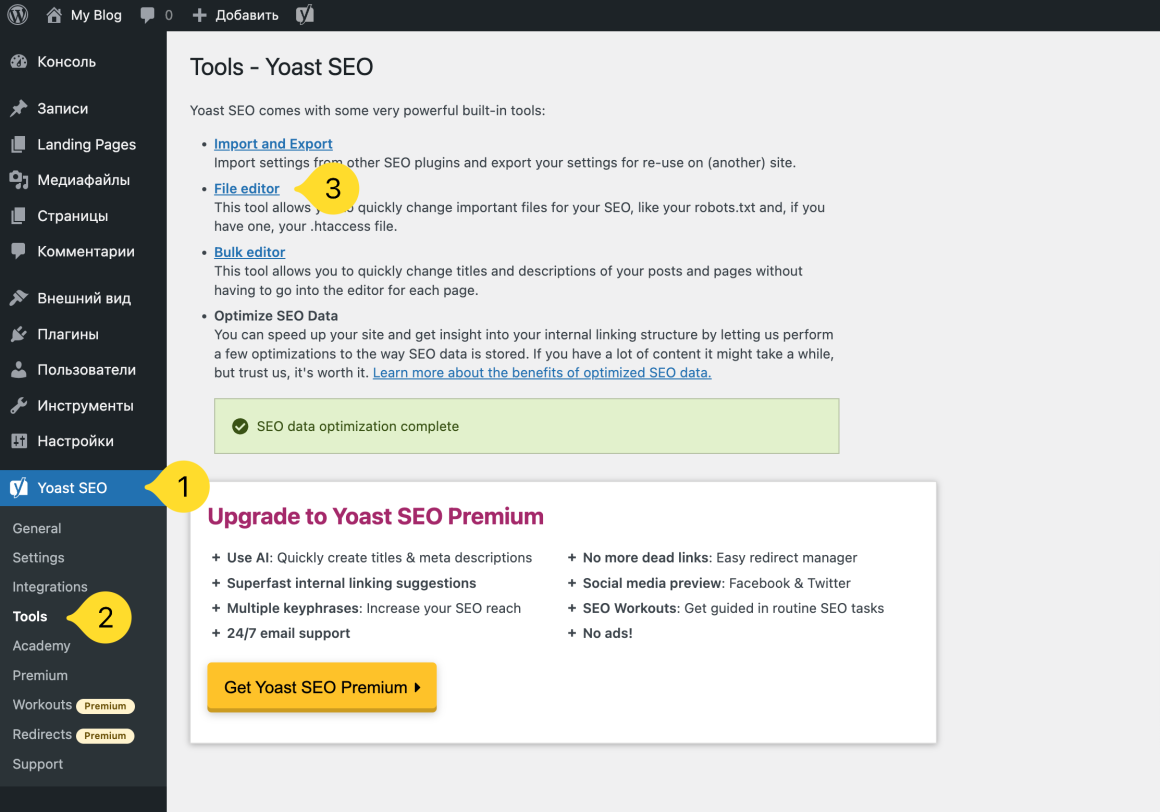
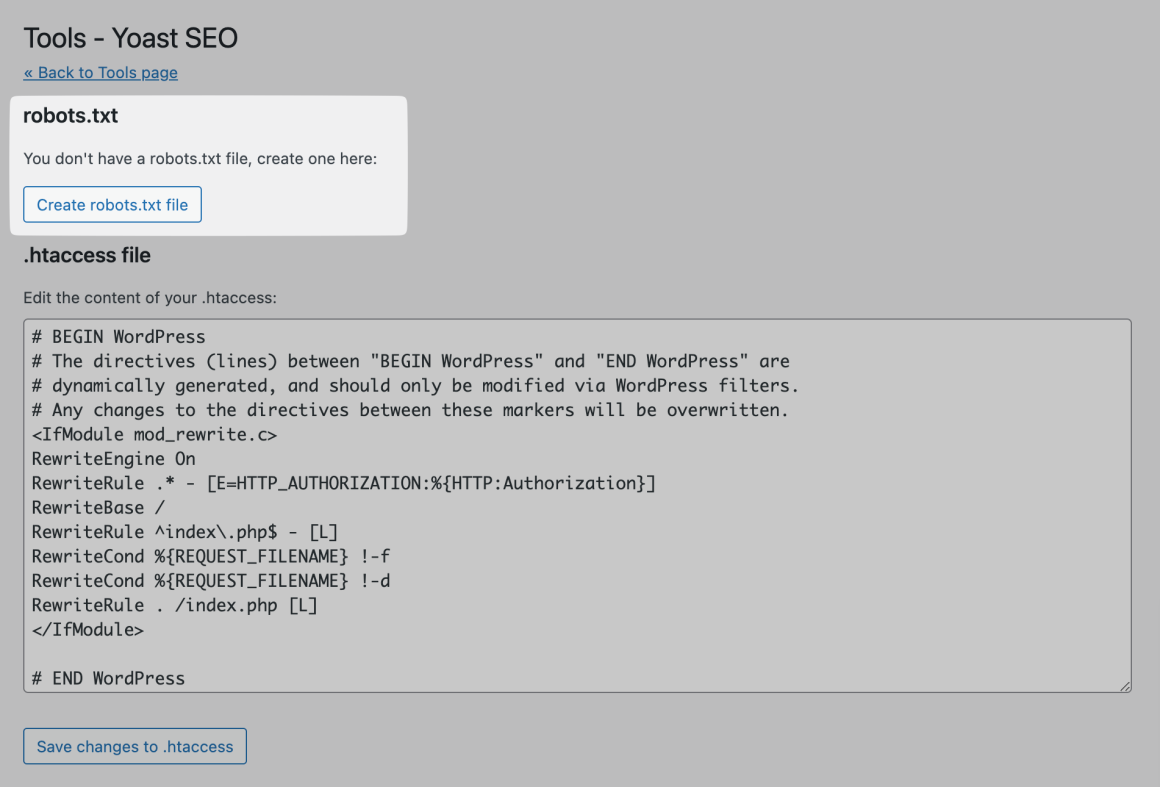
Если файл robots.txt уже создан, вы сможете отредактировать его.
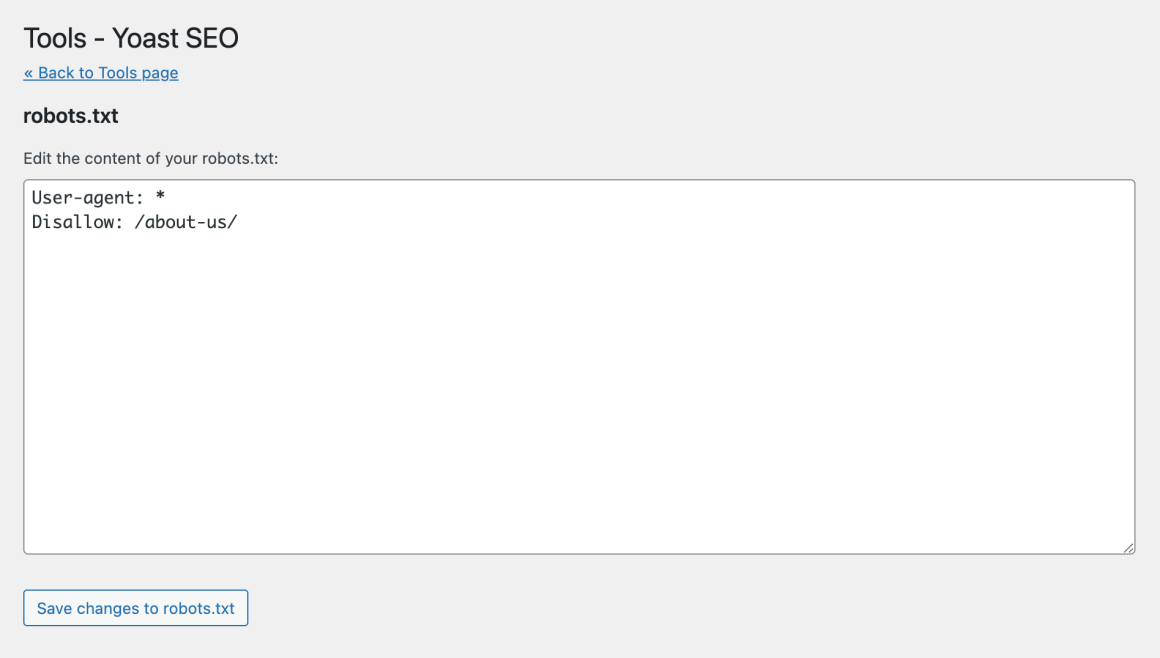
Если у вас нет физического файла, Yoast предложит вам создать файл robots.txt:
🔗 Подробнее о создании robots.txt c Yoast SEO
Если вы интересуетесь поисковой оптимизацией своего сайта, вам следует знать и об этом 👇
Google учитывает скорость сайта при ранжировании
Скорость сайта влияет на то, как посетитель воспринимает страницы, поэтому с 2018 года она стала одной из метрик, учитываемой Google при ранжировании. Если посетитель не дождался, пока загрузится страница и закрыл вкладку, это минус в карму и рейтинг поисковой выдачи.
Позаботьтесь о скорости своего сайта — разместите его на хостинге с чистыми SSD-дисками 🚀
Мы отказались от HDD-дисков на серверах и перешли на SSD. На SSD-дисках сайты загружаются в пять раз быстрее, чем на HDD.
Также мы заменили веб-сервер Apache на LiteSpeed, чтобы увеличить скорость работы сайтов. По статистике, на LiteSpeed файлы открываются в 5 раз быстрее. А если ваш сайт на WordPress, то мы ускорим его еще больше с плагином LSCache.
Наш хостинг можно бесплатно тестировать в течение 30 дней. Убедитесь, что ваш сайт работает с нами быстрее — и тогда уже будете принимать решения по покупке 🔥
Как редактировать robots.txt WordPress-сайта с помощью All in One SEO
Если вы используете другой популярный SEO-плагин All in One SEO Pack, он самостоятельно создает файл robots.txt со стандартными для WordPress настройками. Также можно добавлять собственные правила и редактировать файл robots.txt прямо из интерфейса плагина.
Все, что вам нужно сделать, это перейти в раздел All in One SEO → Инструменты и найти переключатель Включить произвольный robots.txt.
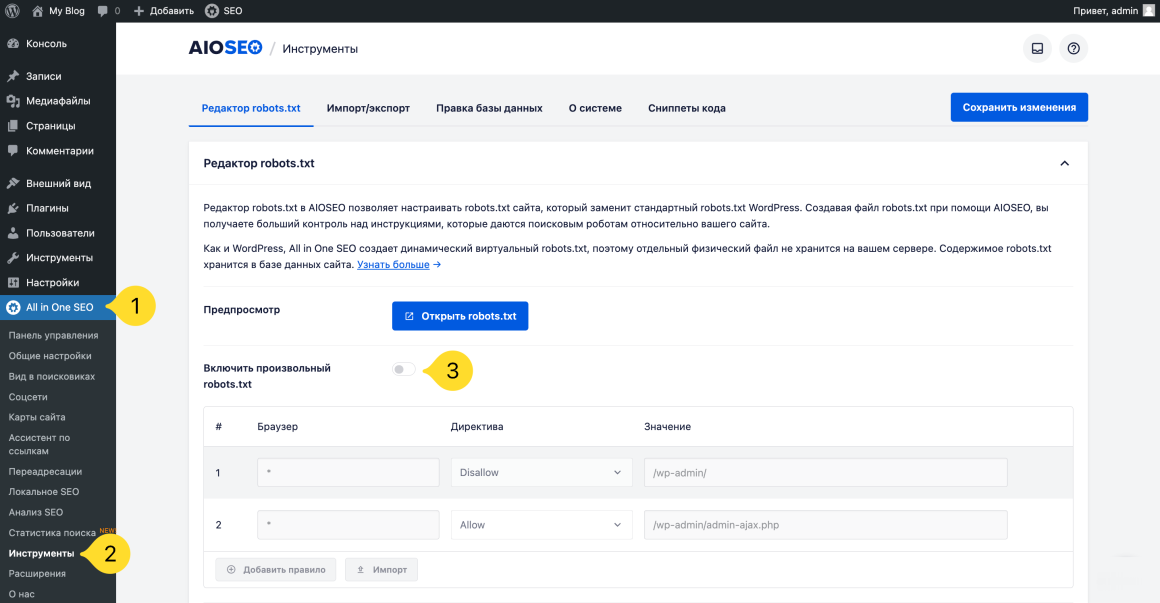
Переведите переключатель во включенное положение. В строках ниже можно создавать собственные правила и добавлять их в файл robots.txt.
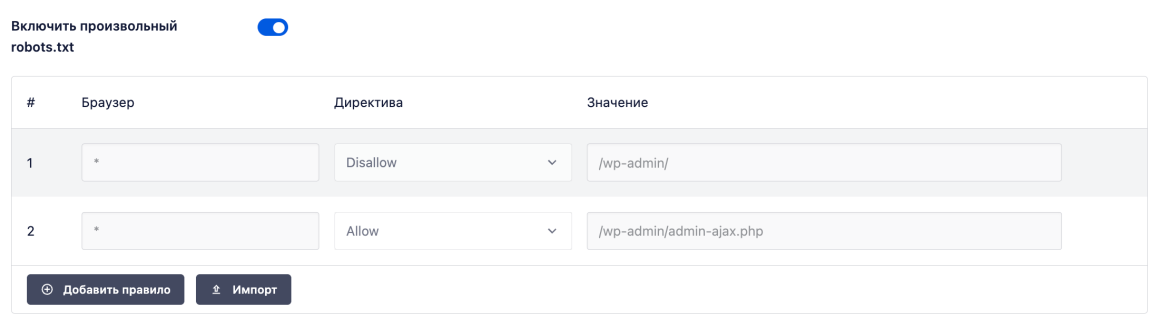
Не забудьте нажать кнопку Сохранить изменения в правом верхнем или нижнем углу.
🔗 Подробнее о создании robots.txt с All in One SEO
Как создать и редактировать файл robots.txt через FTP
Если вы не используете ни один SEO-плагин, позволяющий создавать и редактировать robots.txt в админпанели, вы можете создать файл и управлять им через FTP или панель управления хостингом.
С помощью любого текстового редактора создайте пустой файл с именем robots.txt, затем подключитесь к своему сайту через SFTP и загрузите этот файл в корневую папку вашего сайта. Вы можете вносить дальнейшие изменения в файл robots.txt, редактируя его через SFTP или загружая новые версии файла.
Другой вариант — создать и редактировать файл через панель управления хостингом. Мы используем на нашем виртуальном хостинге панель cPanel. Чтобы создать файл в ней, перейдите в раздел Менеджер файлов.
Войдите в папку вашего домена и нажмите + Файл вверху. Назовите файл «robots.txt» и нажмите Create New File.
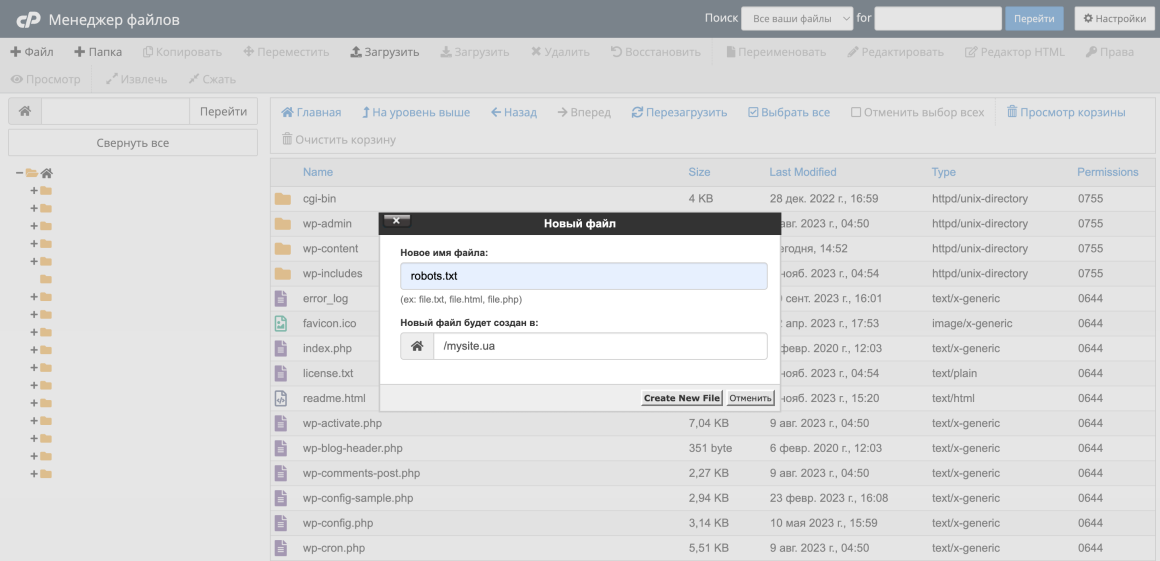
Чтобы внести записи в файл, щелкните по нему правой кнопкой мыши и выберите Edit и еще раз Edit.
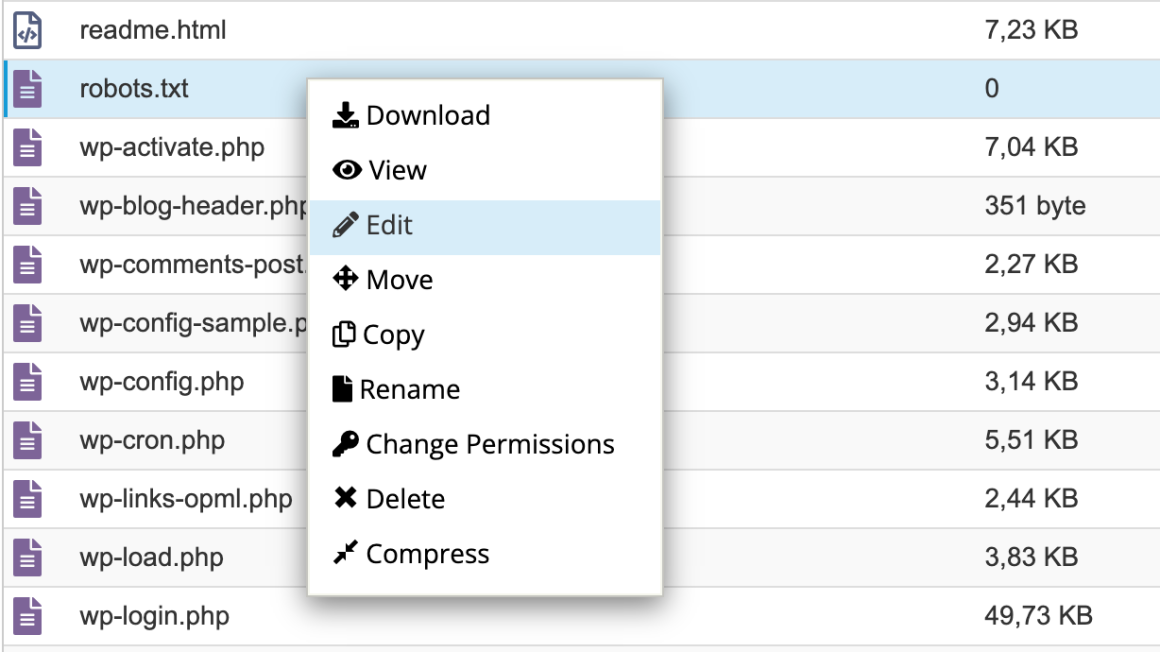
Что нужно добавить в файл robots.txt
Теперь на вашем сервере есть файл robots.txt, который вы можете редактировать при необходимости. Давайте разбираться, что все-таки в нем писать на практике.
Как мы писали в первом разделе, robots.txt позволяет контролировать взаимодействие роботов с вашим сайтом. Вы делаете это с помощью двух основных команд:
- User-agent — позволяет нацеливаться на конкретных ботов. Пользовательские агенты — это то, что боты используют для идентификации. С их помощью можно, например, создать правило, которое будет применяться к Bing, но не к Google.
- Disallow — позволяет запретить роботам доступ к определенным частям вашего сайта.
Существует также команда Allow, которую можно использовать в нишевых ситуациях. По умолчанию все на вашем сайте обозначено Allow, поэтому в 99% ситуаций в этой команде нет необходимости. Но она пригодится, если вы хотите запретить доступ к папке и ее дочерним папкам, но разрешить доступ к одной конкретной дочерней папке или файлу.
Вы добавляете записи в robots.txt в следующем порядке:
- к какому User-agent должно применяться правило,
- какие именно правила следует применить с помощью команд Disallow и Allow.
Существуют также некоторые другие команды, такие как Crawl-delay и Sitemap , но они:
- или игнорируются большинством основных поисковых систем или интерпретируются очень по-разному (в случае задержки сканирования, Crawl-delay);
- или стали ненужными за счет таких инструментов как Google Search Console (для карт сайта, Sitemap).
Давайте рассмотрим конкретные случаи использования, как это все сочетается.
Статья по теме:

Как использовать Disallow в файле robots.txt для блокировки доступа ко всему сайту
Предположим, вы хотите заблокировать доступ к вашему сайту для всех поисковых роботов. Это вряд ли произойдет на «живом» сайте, но это может пригодиться для сайта на стадии разработки. Для этого нужно добавить к вашему файлу robots.txt такой Disallow код:
User-agent: *
Disallow: /Что происходит в этом коде:
- Звездочка * рядом с User-agent означает «все пользовательские агенты». Звездочка — это символ подстановки, который означает, что правило применимо к каждому User-agent.
- Косая черта / рядом с Disallow означает, что вы хотите запретить доступ ко всем страницам, содержащим «yourdomain.com/», то есть к каждой странице вашего сайта.
Как использовать файл robots.txt, чтобы заблокировать доступ одного бота к вашему сайту
Давайте изменим ситуацию. В этом примере мы представим, что вам не нравится, что Bing сканирует ваши странички. Вы фанат команды Google и не хотите, чтобы Bing даже заглядывал на ваш сайт. Чтобы запретить сканирование вашего сайта только Bing, вам нужно заменить символ подстановки * на Bingbot:
User-agent: Bingbot
Disallow: /Теперь в приведенном выше коде говорится о применении правила Disallow только к ботам с User-agent Bingbot.
Вряд ли на практике вы захотите заблокировать доступ к Bing, но этот сценарий может пригодиться, если есть определенный бот, которому вы не хотите разрешать доступ к вашему сайту. На сайте UserAgentString.com есть хороший список известных имен User-agent большинства сервисов.
Как использовать robots.txt для блокировки доступа к определенной папке или файлу
Для этого примера допустим, что вы хотите заблокировать доступ только к определенному файлу или папке (и всем подпапкам этой папки). Чтобы применить это к WordPress, скажем, вы хотите заблокировать:
- всю папку wp-admin;
- файл wp-login.php.
Вы можете воспользоваться следующими командами:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-login.phpУказывайте правила с учетом регистра. Например, правило:
User-agent: *
Disallow: /file.asp
распространяется на URL https://www.example.com/file.asp, но не на https://www.example.com/FILE.asp.
Как использовать файл robots.txt, чтобы предоставить роботам полный доступ к вашему сайту
Если у вас нет причин блокировать доступ роботов к любым страницам вашего сайта, вы можете добавить следующую команду:
User-agent: *
Allow: /Или альтернативно:
User-agent: *
Disallow:Как с помощью robots.txt разрешить доступ к определенному файлу в запрещенной папке
Теперь допустим, что вы хотите заблокировать целую папку, но хотите разрешить доступ к определенному файлу в этой папке. Вот где пригодится команда Allow. И она действительно очень применима к WordPress. Виртуальный стандартный файл WordPress robots.txt прекрасно иллюстрирует этот пример:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpЭтот фрагмент блокирует доступ ко всей папке /wp-admin/, за исключением файла /wp-admin/admin-ajax.php.
Как использовать robots.txt, чтобы запретить ботам сканировать результаты поиска в WordPress
Одна из специфических для WordPress настроек, которую вы можете сделать, — запретить поисковым роботам сканировать страницы результатов поиска. По умолчанию WordPress использует параметр запроса «?s=».
Поэтому, чтобы заблокировать доступ, все, что вам нужно сделать, это добавить следующее правило:
User-agent: *
Disallow: /?s=
Disallow: /search/Это может быть эффективным способом остановить «мягкие» ошибки 404 , если вы их получаете.
🔗 10 лучших плагинов WordPress для поиска на сайте
Как создать разные правила для разных ботов в файле robots.txt
До этого момента все примеры относились к одному правилу за раз. Но бывают ситуации, когда нужно применить разные правила для разных ботов. Тогда нужно просто добавить каждый набор правил под соответствующим User-agent для каждого бота.
Например, если вы хотите создать одно правило, которое применимо ко всем ботам, и другое правило, которое применимо только к Bingbot, вы можете сделать это следующим образом:
User-agent: *
Disallow: /wp-admin/
User-agent: Bingbot
Disallow: /В этом примере всем ботам будет заблокирован доступ к /wp-admin/, но Bingbot будет заблокирован доступ ко всему вашему сайту.
При покупке на год — скидка 20%
Как проверить файл robots.txt
Если robots.txt создан неправильно:
- Некоторые страницы, которые вы не хотите показывать в поисковиках, могут все равно отображаться в результатах поиска.
- Или наоборот, важные страницы вашего сайта могут быть заблокированы для поисковиков, что может снизить количество посетителей.
- Новый контент может не появляться в поисковиках или появляться с большой задержкой.
- Это может привести к меньшему трафику на сайте и ухудшению его рейтинга в поисковиках.
Чтобы убедиться, что ваш файл robots.txt настроен правильно и работает должным образом, нужно тщательно его протестировать.
Google Search Console
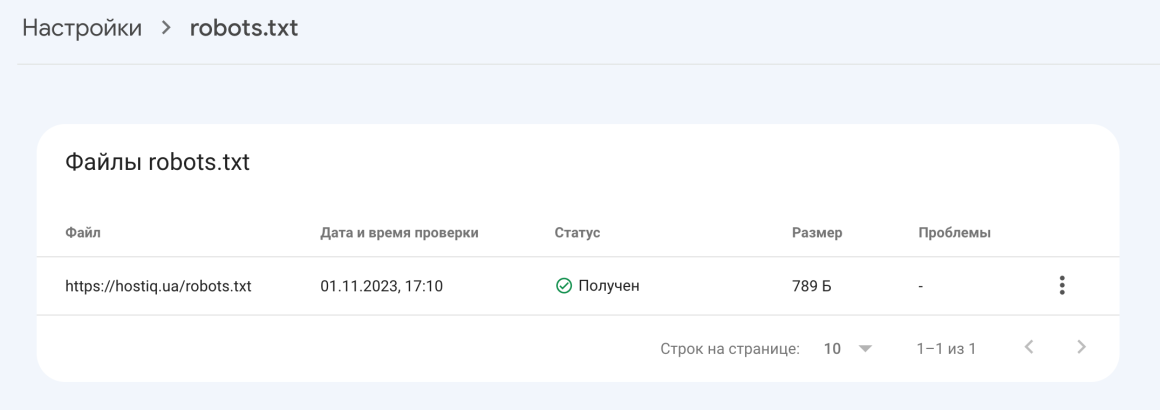
В Google Search Console есть отчет robots.txt. Это простой в использовании инструмент, который выявляет потенциальные проблемы в файле robots.txt.
Просто перейдите в инструмент и выберите ресурс, который вы хотите проверить. Также вы можете перейти в этот отчет прямо из Google Search Console → раздел Настройки → Открыть отчет напротив robots.txt.
Отчет robots.txt показывает, какие файлы robots.txt Google нашел для вашего сайта, дату последнего сканирования, а также какие-либо предупреждения или возникшие ошибки. В отчете также можно запросить повторное сканирование файла robots.txt в экстренных ситуациях: например, когда вы обновили файл важными правилами и хотите, чтобы Google как можно скорее о них узнал.
Статья по теме:

Logeix
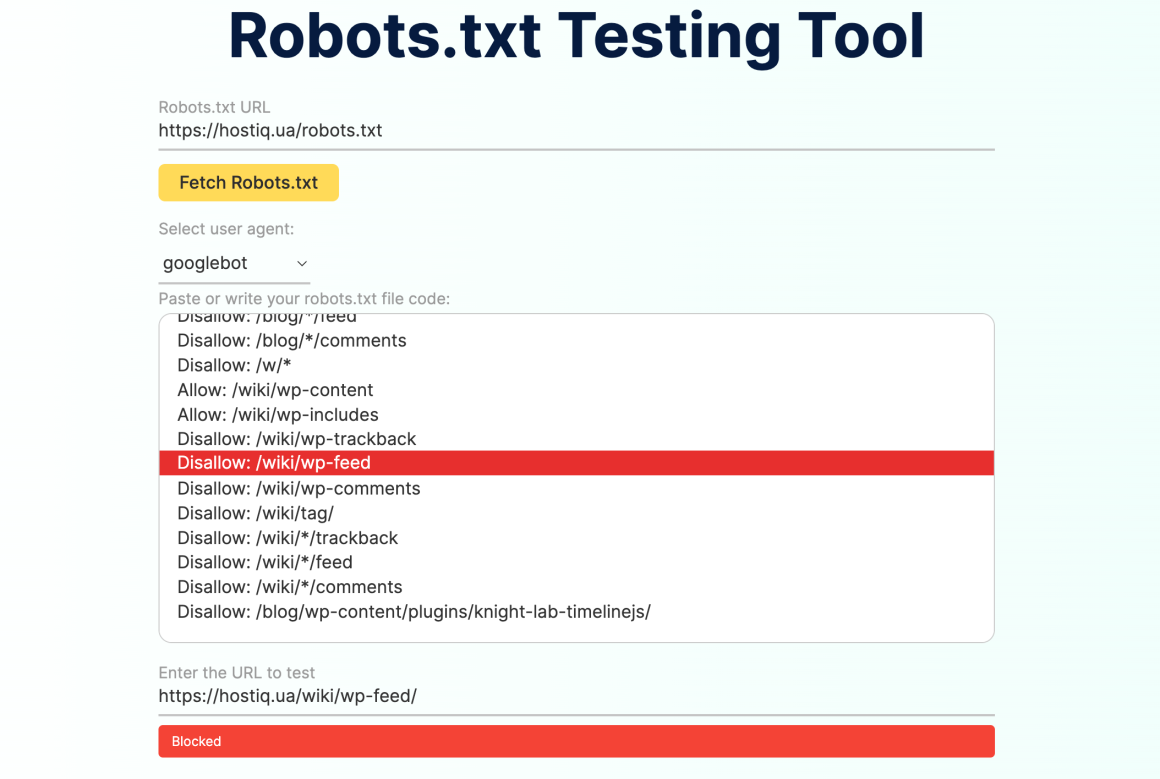
Также для проверки robots.txt можно использовать удобные сторонние сервисы вроде Logeix.
Введите URL-адрес robots.txt сайта, который хотите проверить, или просто вставьте код файла robots.txt. В строке «Select user agent» можно выбрать, от какого User-Agent вы хотите запустить тест. После этого введите адрес страницы, которую вы хотите проверить, и инструмент сообщит, доступна ли она для сканирования или заблокирована robots.txt.
Если страница доступна для сканирования, вы увидите зеленый ответ «Crawlable». Если правила файла запрещают сканировать страницу, вы получите красную надпись «Blocked», а в поле выше сервис подсветит строку с блокирующим правилом сканирования.
🔗 25 SEO-инструментов, которые могут вам пригодиться
Что еще нужно знать о файле robots.txt
Два важных момента, которые вам стоит знать перед созданием своего robots.txt.
Остерегайтесь UTF-8 BOM
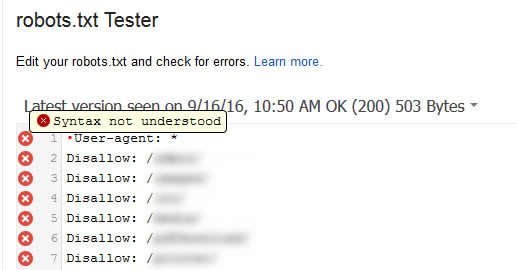
BOM расшифровывается как byte-order mark, маркер порядка байтов. Это невидимый символ, который иногда добавляют в файлы старые текстовые редакторы. Если это случится с файлом robots.txt, Google может прочитать его неправильно. Вот почему важно проверять файл на наличие ошибок.
К примеру, как показано ниже, файл содержал невидимый символ, и Google жаловался на то, что синтаксис не ясен. В результате такая невидимая штука делала строчки файла robots.txt вообще недействительными.
В статье Гленна Гейба вы можете прочитать подробнее, как UTF-8 Bom может убить ваше SEO.
Googlebot в основном базируется в США
Также важно не блокировать Googlebot из Соединенных Штатов, даже если вы нацелены исключительно на Украину. Иногда боты осуществляют локальный поиск, но Googlebot в основном базируется в США.
📌 В завершение статьи о robots.txt для сайта WordPress хотим еще раз подчеркнуть, что команда Disallow в этом файле не равна тэгу noindex. Robots.txt блокирует сканирование, но не обязательно запрещает индексацию. Файл рекомендует поисковым системам и другим ботам, как они должны взаимодействовать с вашим сайтом, но не контролирует, будет ли ваш контент действительно проиндексирован.
Большинству обычных пользователей WordPress не нужно изменять стандартный файл robots.txt. Но если вас донимает конкретный бот или вы хотите ограничить взаимодействие поисковых систем с определенными страницами, вы можете добавить свои правила с помощью SEO-плагинов, или вручную загрузив файл robots.txt в корневую папку вашего сайта.