В прошлой статье «Как добавить сайт в поисковые системы» мы рассказали, как сообщить поисковым роботам о новом сайте или страницах. Но после добавления сайта в поисковые системы, он все еще может не индексироваться в Google. Что еще хуже, поисковые роботы сканировали сайт раньше, но теперь сайт не индексируется.
Единственный выход в этой ситуации ― проверить возможные причины, которые влияют на индексацию сайта. Об этих причинах расскажем в статье.

Сайт закрыт от индексации в Robots.txt
Одна из самых распространенных причин, из-за которой сайт не индексируется ― запрет на индексацию в файле robots.txt. Часто разработчики сайта хранят тестовую версию на отдельных доменах или поддоменах. Тестовый сайт закрывают от индексации с помощью robots.txt. Когда сайт уже готов, содержимое тестовой версии вместе с файлом robots.txt попадает на рабочий домен. Файл robots.txt забывают изменить и сайт становится недоступным для поисковых роботов.
Файл robots.txt находится в корневой папке сайта — https://mysupersite.com/robots.txt
Если страница закрыта от индексации, содержимое файла может выглядеть следующим образом:
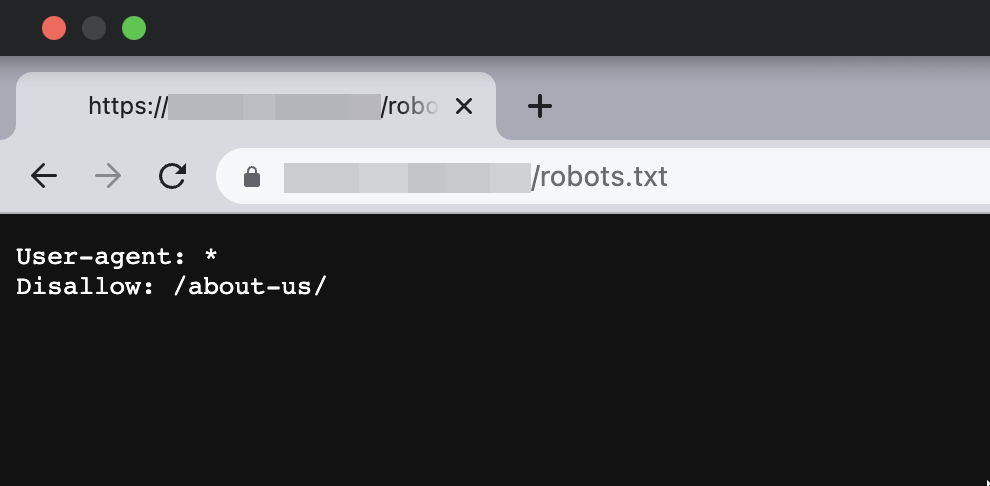
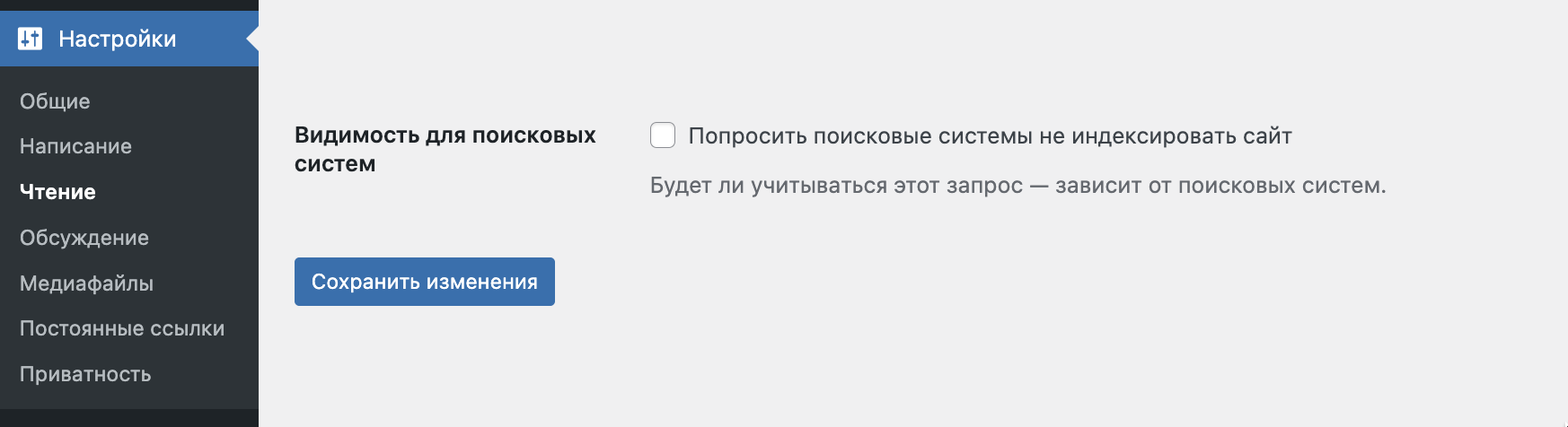
Если у вас сайт на CMS WordPress, проверьте настройки индексации в панели управления сайтом. Зайдите в раздел Настройки → Чтение. Поле Видимость для поисковых систем должно быть пустым:
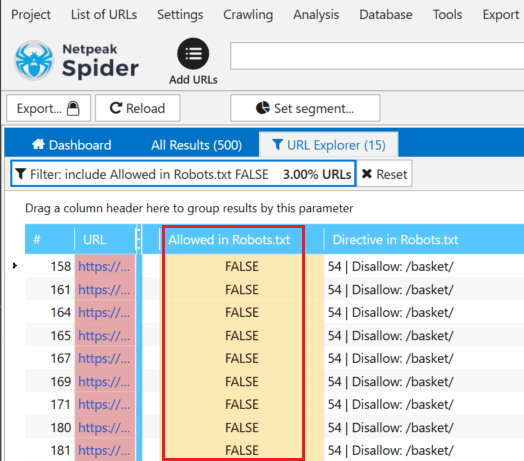
Как проверить Robots.txt
При помощи следующих инструментов можно проверить не закрыт ли через robots.txt от индексации сайт или определенные страницы:
- Инструменты проверки robots.txt
Предварительно нужно добавить сайт в панель вебмастеров Google, чтобы проверить robots.
👉 Для проверки также можно воспользоваться сторонними сервисами, например
- https://technicalseo.com/tools/robots-txt/
- https://sitechecker.pro/ru/robots-tester/
- https://www.websiteplanet.com/ru/webtools/robots-txt/
- Инструменты для вебмастеров
Если еще не пользуетесь данными сервисами, читайте статью: Как добавить сайт в инструменты веб-мастеров.
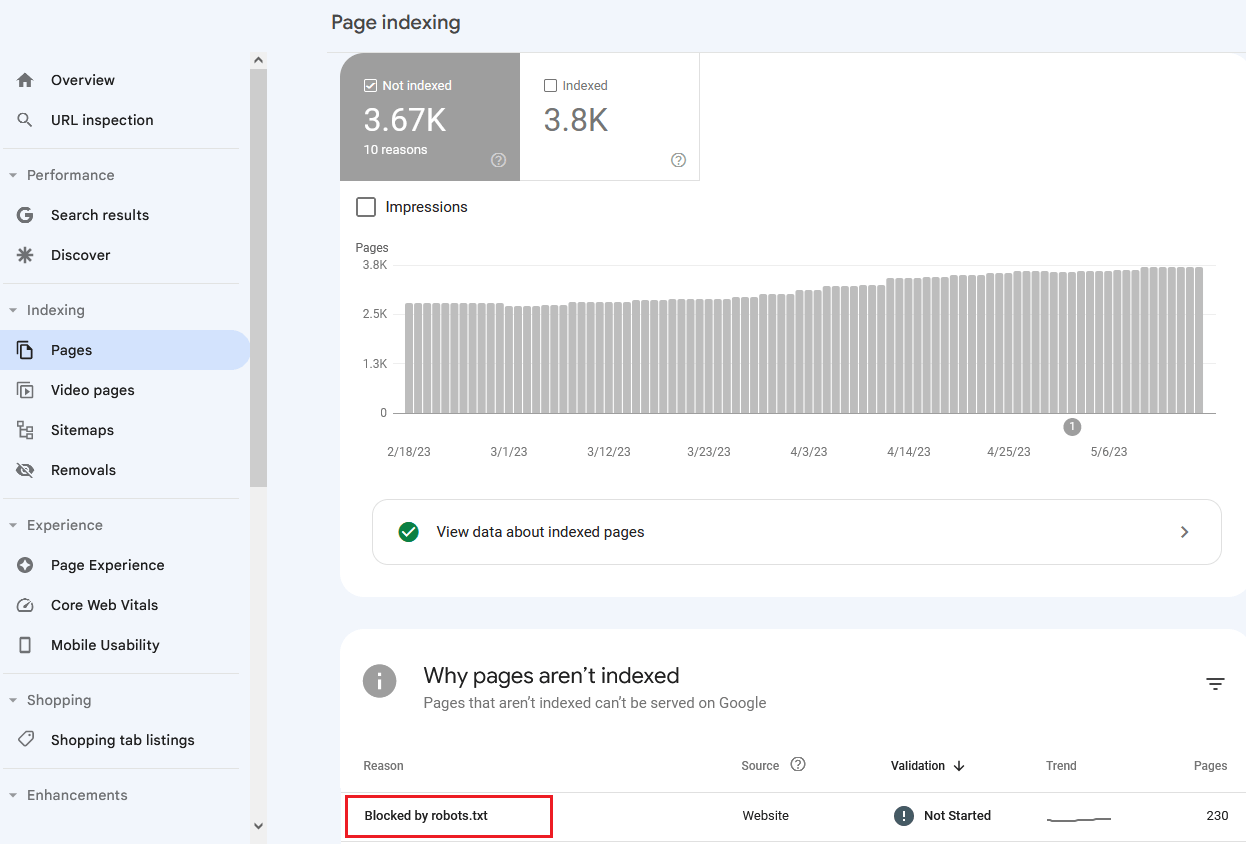
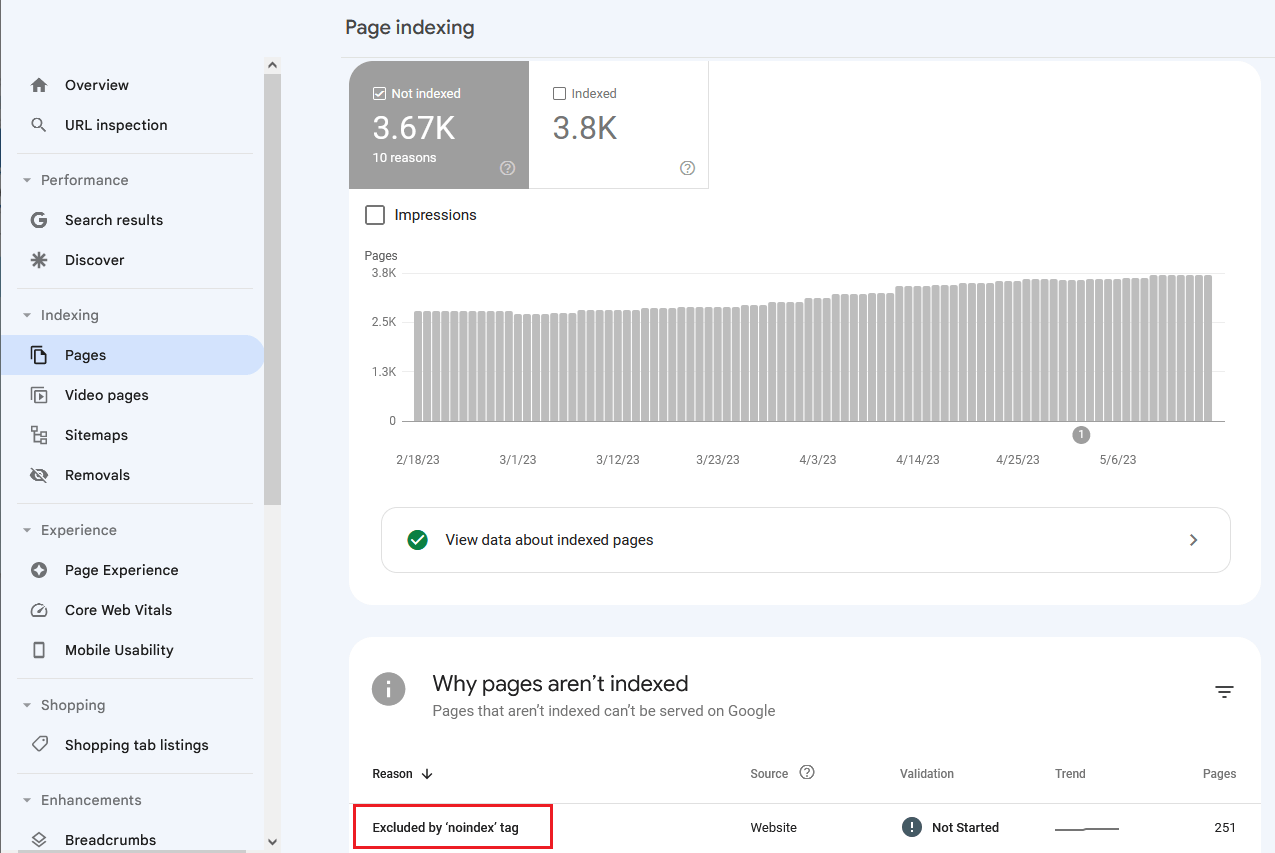
В Google Search Console перейдите в раздел Индексирование → Страницы → таблица Почему эти страницы не индексируются.
- Программы для проведения аудита внутренней оптимизации сайта
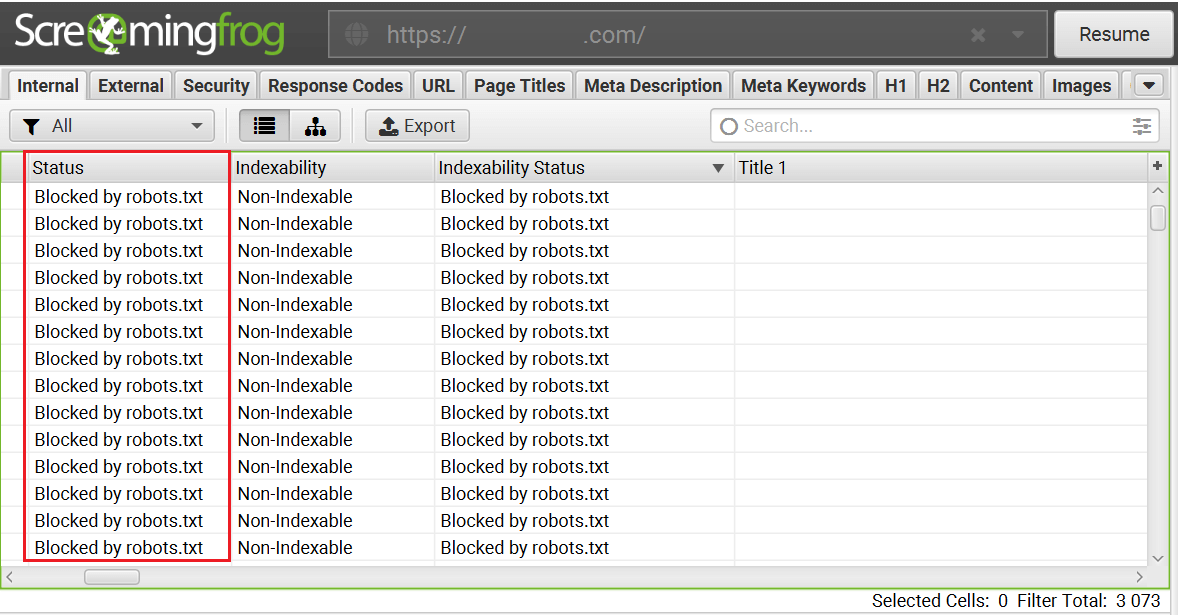
После сканирования сайта или определенных страниц, в результатах отчета будут показаны страницы, которые недоступны для индексации:
Screaming Frog SEO Spider
Netpeak Spider
Читайте также: SEO-сервисы для анализа и проверки сайта
Метатеги Robots
Проверьте наличие метатега robots в коде страницы. Его размещают между тегами <head></head>. Выглядеть этот тег может следующим образом:
<meta name=“robots” content=“noindex”>Метатег robots сообщает поисковым роботам о том, что страницу индексировать не нужно.
Как проверить метатеги Robots
- Инструменты для вебмастеров
В Google Search Console перейдите в раздел Индексирование → Страницы → таблица Почему эти страницы не индексируются.
- Программы для проведения аудита внутренней оптимизации сайта
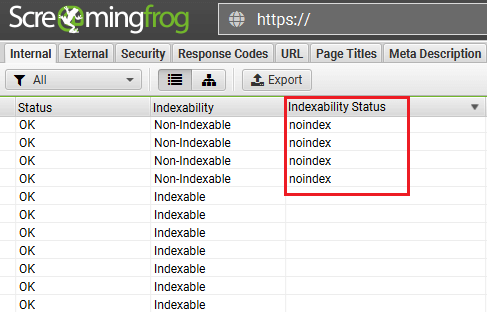
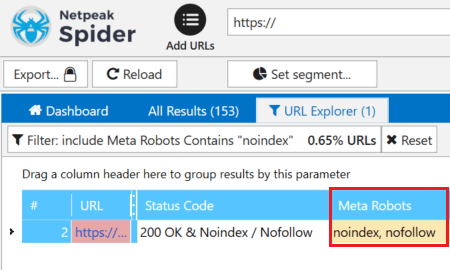
Обнаружить страницы, которые закрыты от индексации с помощью метатегов robots, можно с помощью программ для аудита внутренней оптимизации сайта.
Screaming Frog SEO Spider
Netpeak Spider
При покупке на год — скидка 20%
Файл .htaccess
Файл .htaccess содержит правила работы веб-сервера. Обычно этот файл размещают в корневой директории веб-сервера (/public_html) либо в корневой директории сайта (/public_html/mysupersite.com/).
С помощью некоторых правил в .htaccess можно закрыть сайт от индексации. Например, можно закрыть доступ для всех посетителей, кроме нужного IP адреса:
order allow,deny
deny from all
allow from IPИли можно разрешить доступ всем, кроме нужного IP:
order allow,deny
deny from UndesiredIP
allow from allПроверьте файл .htaccess на вашем сервере, возможно в нем прописаны запрещающие правила для индексирования.
Более подробно узнать о директивах и правилах можно в нашей статье: Файл htaccess.
Rel Canonical
Тег rel=”canonical” применяют на страницах с одинаковым содержимым. Этот тег указывает поисковым роботам адрес страницы, которая является основной.
Рассмотрим на примере две страницы, которые имеют одинаковое содержание:
- https://mysupersite.com/original-page/ — основная страница;
- https://mysupersite.com/dublicat-page/ — страница с дублирующим содержанием.
Чтобы в индексе была основная страница, можно применить тег rel=”canonical”. В html код страницы https://mysupersite.com/dublicat-page/ между тегами <head></head> нужно добавить следующий тег:
<link rel="canonical" href="https://mysupersite.com/original-page/" />Если ваша страница или страницы не индексируются, проверьте наличие тега rel=”canonical” в html-коде и его корректность.
Статья по теме:

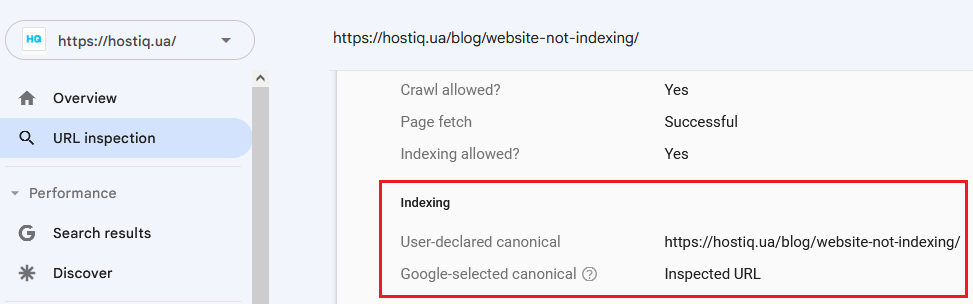
Как проверить наличие тегов rel=”canonical”
- Google Search Console в разделе Проверка URL.
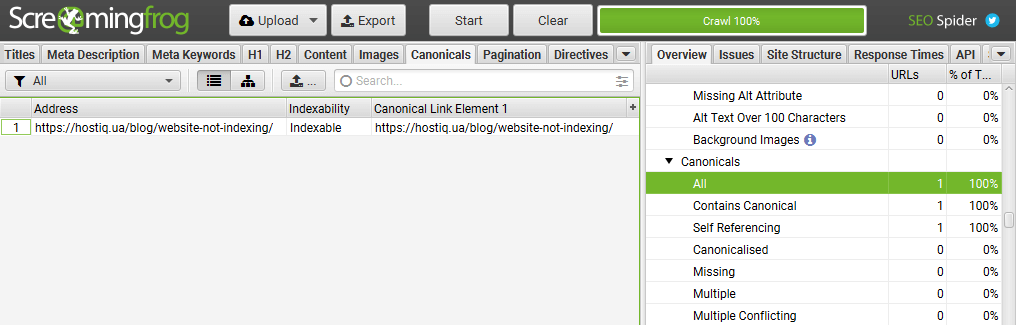
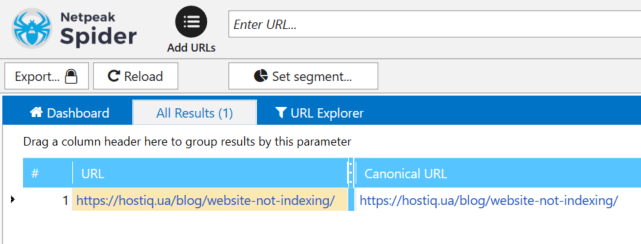
- Screaming Frog, Netpeak Spider или другие подобные программы
X‑Robots-Tag
X‑Robots-Tag ― это директива в заголовках ответа сервера, с помощью которой можно запретить роботам индексировать конкретные страницы или файлы. Пример HTTP-ответа сервера с директивой X‑Robots-Tag, которая запрещает индексацию страницы:
HTTP/1.1 200 OK
Date: Tue, 19 May 2020 22:34:11 GMT
(…)
X-Robots-Tag: noindex
(…)Этот тег можно использовать в конфигурации сервера. На серверах Apache он добавляется в файл .htaccess, на серверах Nginx в файл conf.
Рассмотрим на примере, как выглядит запрет на индексацию файлов .doc через X-Robots-Tag:
Фрагмент кода в файле .htaccess для сервера Apache
<Files ~ "\.doc$">
Header set X-Robots-Tag "noindex, nofollow"
</Files>Фрагмент кода в файле conf для сервера Nginx
location ~* \.doc$ {
add_header X-Robots-Tag "noindex, nofollow";
}Дополнительную информацию о данном HTTP-заголовке можно получить в справке Google.
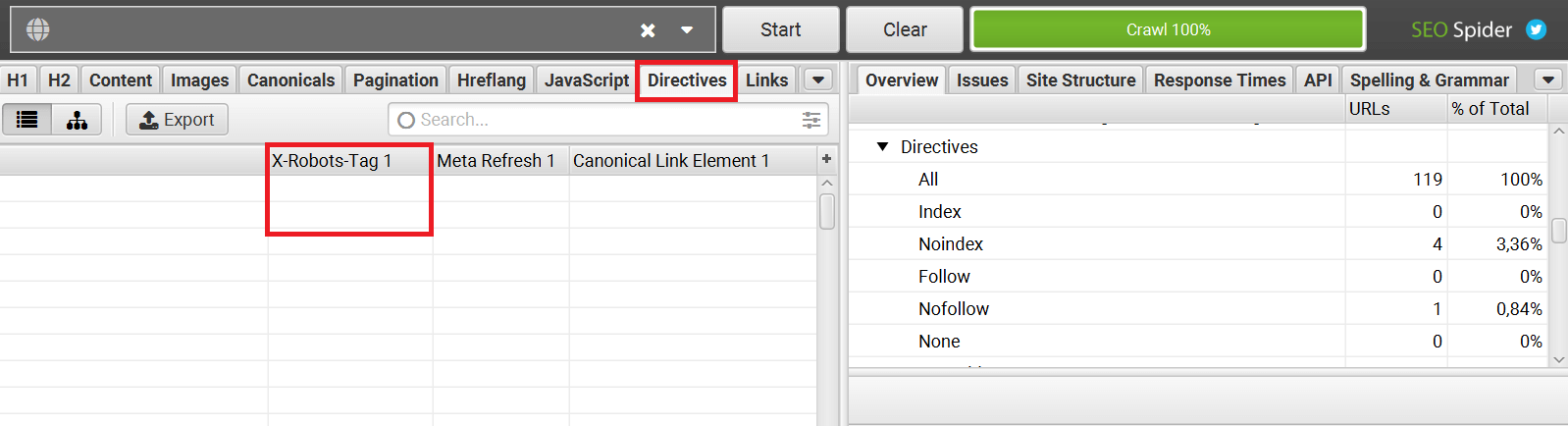
Как проверить наличие X‑Robots-Tag на страницах сайта
Плагин Web Developer для браузеров:
Сервисы или программы для аудита сайта — Screaming Frog, Netpeak Spider и другие аналоги:

Долгий ответ сервера
Время ответа сервера ― это время, за которое запрос клиента в браузере доходит до сервера и клиент получает ответ сервера. Время отклика измеряется в TTFB (Time To First Byte) ― время до первого байта, или сколько миллисекунд прошло между вашим запросом и ответом сервера. Google рекомендует стремиться к тому, чтобы время отклика было менее 200 миллисекунд. TTFB больше 500 мс уже является проблемой.
Если при обращении поискового робота к серверу, он получает долгий ответ, то робот может не просканировать часть страниц.
Как проверить время ответа сервера
Проверить время ответа сервера можно с помощью сервисов:
Статья по теме:

Возможные причины долгого ответа сервера
Среди возможных причин можно выделить следующие:
- недостаточный объем ресурсов сервера: слабый процессор, недостаточно памяти;
- не оптимизирована работа сервера;
- отсутствие оптимизации скорости загрузки сайта. Не минимизированы файлы CSS/JS, не сжаты изображения и т.д.
- отсутствие кэширования.
Если вы оптимизировали скорость загрузки сайта, но у вас остались проблемы с долгим ответом сервера, стоит попробовать другие хостинги. Например, мы предлагаем виртуальный хостинг с серверами в Украине, Нидерландах и США.
Ваш сайт более требовательный и нужно больше мощностей? Не проблема. У нас есть VIP пакеты с большим объемом ресурсов или можно взять VPS.
Возьмите хостинг на тест и проверьте сами. 30 дней бесплатно! 🔥
Пробуйте надежный хостинг с аптаймом 99,9%!
Наша теплая поддержка на связи 24/7

Неверный ответ сервера
Проверьте код ответа сервера. Убедитесь, что нужные вам страницы отдают код 200. Этот код означает, что страница доступна на сервере.
Как проверить ответ сервера
Проверить ответ сервера можно с помощью инструментов:
- Google Search console
- httpstatus.io
- Netpeak Spider, Screaming Frog или другие подобные программы.
Также можно использовать различные плагины для браузеров или можно проверить в самом браузере ― F12+вкладка Network.
Некачественный контент
Если ваши страницы содержат контент, который не имеет ценности для пользователя, то поисковые роботы могут не индексировать их. В англоязычных статьях можно встретить термин thin content, который описывает данные страницы.
Примером такого контента может быть:
- дублированный контент;
- скопированный контент;
- автоматически сгенерированный контент;
- неинформативные страницы с партнерскими ссылками;
- дорвеи .
Больше деталей про описание некачественного контента и рекомендации для веб-мастеров можно прочитать в справке Google.
Проблемы на стороне поисковых систем
Как говорится ― и на старуху бывает проруха. На стороне поисковых систем тоже могут возникать проблемы. Например, в середине июля 2022 в Google возникли проблемы с индексацией нового контента. Об этом можно прочитать в новости Google confirmed indexing issue affecting a large number of sites.
На такие проблемы в Google оперативно реагируют и исправляют их.
Кратко: почему страницы сайта не индексируются в Google
Подытожим причины, из-за которых страницы сайта могут не индексироваться:
- Сайт закрыт от индексации через
- robots.txt
- метатеги robots
- файл .htaccess
- X-robots-tag
- Ошибки в rel canonical
- Долгий ответ сервера, проблемы с хостингом
- Неверный ответ сервера
- Некачественный контент
- Проблемы на стороне поисковых систем
Для удобства собрали все пункты и рекомендации в чек-лист: почему страница не ранжируется в Google.
Пишите в комментариях, на какую SEO-тему хотите видеть следующие статьи 💬




