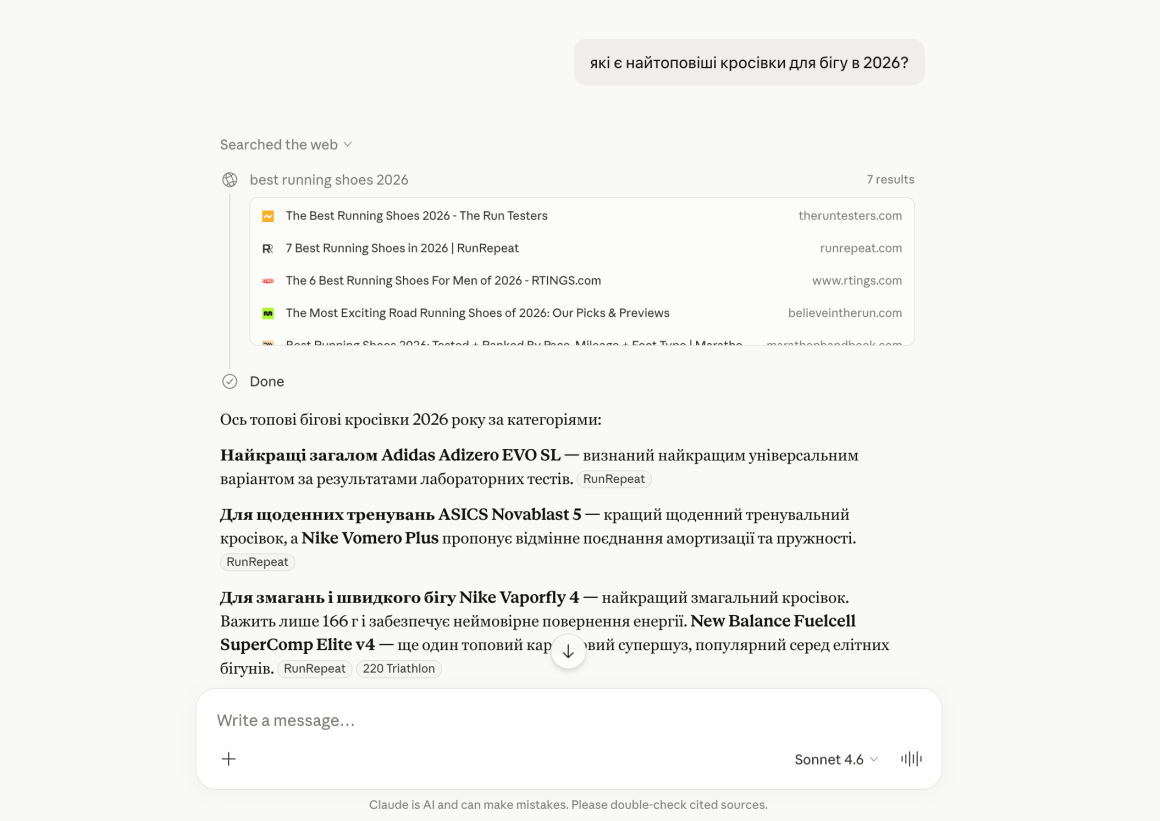
ИИ перехватывает внимание вашего потенциального клиента уже на момент поискового запроса.
Кроме того, все больше людей используют вместо гугла ИИ: ChatGPT, Gemini и другие. В результате пользователь часто получает ответ без перехода на сайты.
Именно поэтому бизнесу недостаточно просто быть в топе Google — важно, чтобы ваш бренд и контент были заметны для ИИ. О том, как это сделать – рассказываем в нашей статье.

Что такое LLM SEO, GEO, AEO
Начнём с небольшого словаря, чтобы мы были на одной волне.
🔎SEO, Search Engine Optimization – это классическая оптимизация под поисковые алгоритмы, чтобы ваш сайт был первым в списке ссылок Google или другого поисковика.
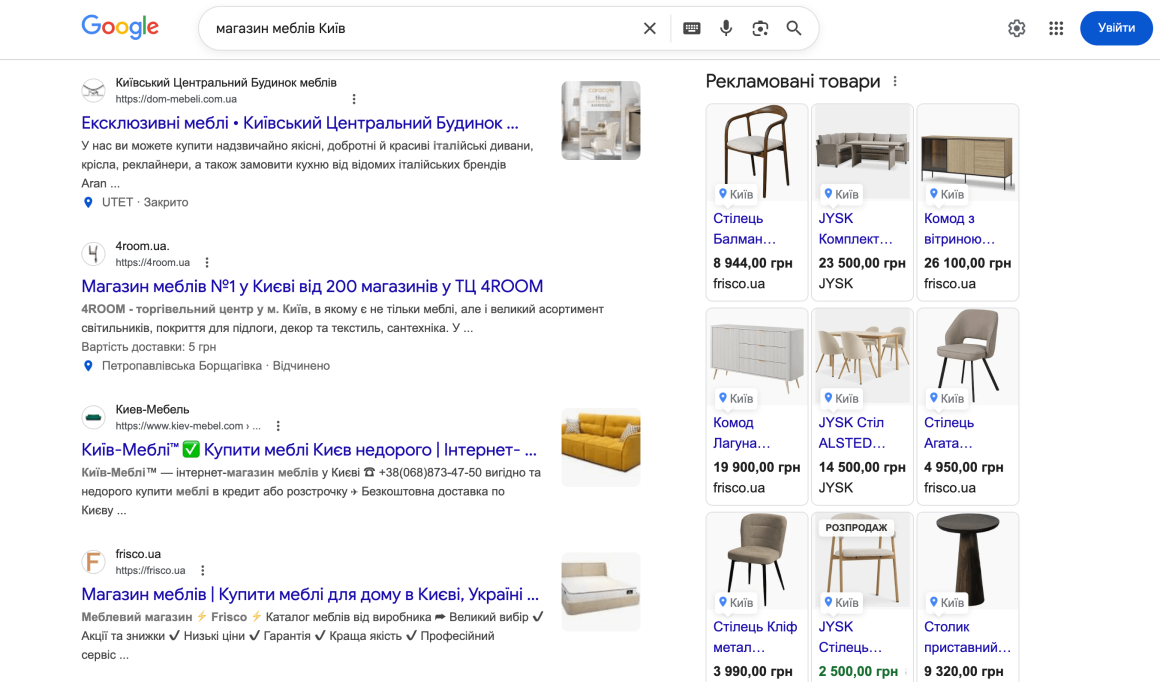
🔎 AEO, Answer Engine Optimization — оптимизация контента под быстрые ответы, чтобы он становился единственным лаконичным ответом на простые вопросы для голосовых помощников или ши-блоков.
🔎 LLM SEO – это продвижение сайта под LLM, глобальные языковые модели. Это оптимизация страниц и контента таким образом, чтобы их использовали и цитировали ChatGPT, Gemini, Claude и другие языковые модели.
🔎 GEO, Generative Engine Optimization — это уже конкретная практика для поисковых систем нового типа на основе искусственного интеллекта, таких как Perplexity или Google AI Overviews.
Граница между последними двумя понятиями очень тонкая. Она заключается в том, знает ли искусственный интеллект ответ заранее. Если он берет ответ из своей базы знаний, на которой он учился, вам нужна оптимизация сайта под LLM. Если он ищет информацию в реальном времени в интернете и на ее основе генерирует ответ – это GEO. Но сейчас большинство ИИ на базе LLM имеют доступ к онлайн-данным, поэтому эти понятия можно использовать взаимозаменяемо.
Чем LLM SEO отличается от классического SEO
После того, как разобрались с определениями, давайте углубимся в то, чем продвижение под нейросети отличается от поисковой оптимизации, то есть классического SEO.
| Критерий | Классическое SEO | LLM SEO |
| Главная цель | Получить позиции и клики по поисковой выдаче | Попасть в AI-ответ, цитату или рекомендацию |
| Единица оптимизации | Страница и ключевой запрос | Смысловой блок, ответ, бренд |
| Как пользователь видит результат | Список ссылок | Сгенерированный ответ с источниками или без них |
| Что важно | Индексация, ссылка, релевантность, поведение, контент | Понятность, цитируемость, структура, внешние упоминания, консистентность |
| Роль бренда | Важна, но часто вторичная | Очень важно: модель должна понимать, кто вы и с чем вас ассоциировать |
| Метрики | Позиции, трафик, CTR, конверсии | Упоминания, цитаты, share of voice, позиция в списках, AI-referral |
Что следует запомнить из этой таблицы:
🧱 ИИ мыслит смысловыми блоками, «кусками» информации, а не страницами. Если в классическом SEO страница и есть единица контента, то для LLM SEO важно, чтобы внутри текста были четкие, лаконичные блоки, которые ИИ-модель может легко вырвать из контекста и цитировать. Это могут быть вопросы-ответы, списки или емкие определения в один абзац.
🧩 Консистентность бренда очень важна. Нейросети обращают внимание на то, чтобы информация о вашем продукте повсюду в интернете — на вашем сайте, в медиа или в отзывах, совпадала. Как быть последовательным в этом – поговорим подробнее со временем.
Однако, пожалуй, самое важное, что мы хотим сказать в этой статье: классическое SEO все равно остается фундаментом для продвижения сайта.
Во-первых, ИИ-поиск строится на основе традиционных поисковых систем. Большинство генеративных движков, такие как Perplexity или Google AI Overviews, не ищут информацию в вакууме — они обращаются к обычным поисковым индексам, чтобы найти свежие и релевантные сайты. Если ваш сайт не оптимизирован технически, плохо индексируется или не имеет авторитета в глазах роботов Google – ИИ о нем просто не узнает.
Во-вторых, доля ИИ-трафика до сих пор сильно уступает классическому поиску. Традиционные поисковики все еще держат львиную долю рынка. К примеру, Ahrefs в своем исследовании обнаружили, что Google приносит в 345 раз больше трафика, чем три основные ИИ системы вместе взятые.
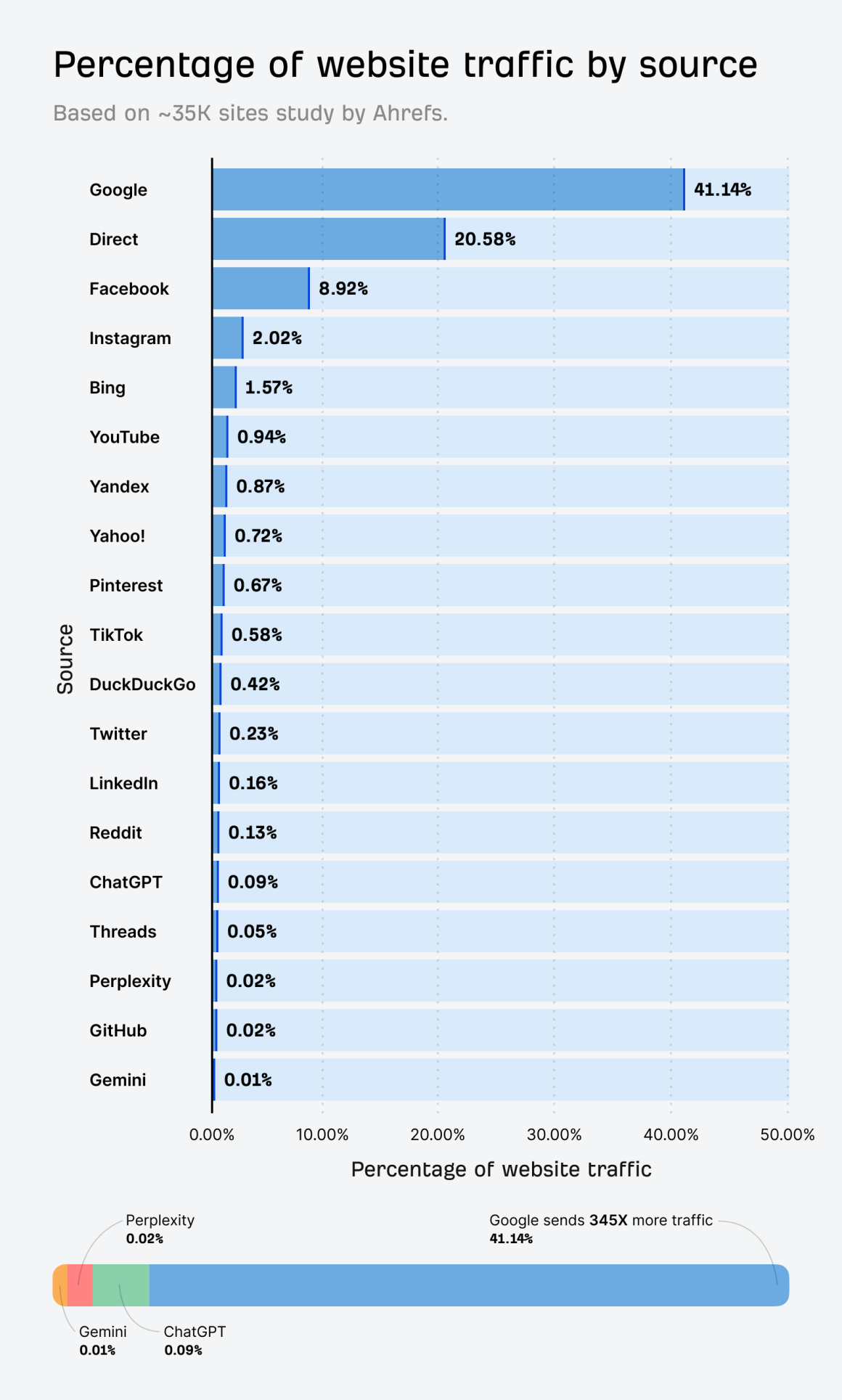
Поэтому продвижение сайта в ChatGPT или других ИИ – это не альтернатива классическому SEO, а следующий уровень онлайн-маркетинга. Вы просто не сможете провести качественную оптимизацию сайта под нейросети, если до этого не был заложен крепкий SEO-фундамент.
Откуда LLM берет информацию о сайтах и брендах
Чтобы понять, как заставить нейросеть рекомендовать именно вас, нужно разобраться, откуда она знает вообще о существовании вашего бизнеса. Искусственный интеллект использует два совершенно разных режима сбора данных, и оптимизироваться нужно под оба.
Учебные данные модели
Это «базовая память» нейросети – колоссальный массив информации, на котором ее обучали разработчики. Сюда входят слепки интернета за прошлые годы: миллиарды онлайн-страниц, книги, статьи из медиа, Википедия, форумы.
Если ваш бренд был крупным, часто упоминаемым и авторитетным на момент обучения модели, она будет помнить о вас по умолчанию даже без доступа к интернету.
Главный минус: эта память статическая. Если модели последний раз «скармливали» данные в 2025 году, то о ваших обновлениях, новых продуктах или смене позиционирования в 2026 году она из датасета ничего не узнает.
Поиск в реальном времени
Когда пользователь запрашивает что-нибудь свежее или специфическое, базовой памяти модели уже не хватает. Тогда включается технология RAG – Retrieval-Augmented Generation, генерация с использованием данных поиска.
ШИ-поисковик делает быстрый запрос в традиционную поисковую систему, Google или Bing, сканирует первые 5–10 сайтов по выдаче, нарезает их контент на куски, анализирует и формирует из них финальный ответ для пользователя.
Главный плюс: это шанс для молодых или обновленных брендов попасть в ИИ-ответы. Даже если вас не было в исходном датасете, качественная оптимизация сайта и высокие позиции в классическом поисковике позволят ИИ найти вас через поиск в реальном времени.
Почему результаты LLM могут отличаться
У выдачи ИИ нет устойчивых позиций — она всегда динамична. То, что ChatGPT хвалит ваш бренд, а Gemini или Perplexity его игнорируют, зависит от трех причин:
- Различные поисковики для Live Search. ChatGPT Search использует индекс Bing, Google AI Overviews опирается на свою базу, а Perplexity комбинирует несколько источников. Если ваш сайт не находится в топе Bing, ChatGPT не найдет его в реальном времени.
- Различный вес источников. У каждой модели есть собственные приоритеты: одна больше доверяет классическим медиа и отраслевым блогам, другая — живым обсуждениям на Reddit, Quora или локальных форумах.
- Контекст и случайность. Нейросети учитывают предварительный диалог с пользователем и имеют встроенный фактор случайности. Поэтому один и тот же бот по одинаковым запросам от двух разных людей выдаст разные рекомендации.
Именно поэтому видимость бренда в нейросетях нужно измерять не по одному запросу, а по набору промптов и динамике повторяющихся упоминаний. Об этом подробнее поговорим в следующих разделах.
Как LLM выбирает источники, компании или сайты
В противоположность классическим поисковикам LLM не ранжирует компании по количеству обратных ссылок или плотности ключевых слов.
В то время как ИИ выбирает, какую именно компанию добавить в ответ, он обращает внимание на следующие факторы:
- Четкая связь бренда с категорией. ИИ должен четко понимать вашу идентичность. Если вы последовательно повсюду упоминаетесь как CRM для логистики, модель вероятнее вытащит вас под этот запрос. Если связь размыта – вас проигнорируют.
- Частота и контекст упоминаний. Имеет значение не просто количество ссылок, а то, что именно о вас пишут, ведь ИИ анализирует тональность контента. Положительный контекст в авторитетных обзорах дает бренду сильный толчок.
- Доверие к источникам. Если о вашей компании написано на DOU, TechCrunch или в Википедии, для LLM это более весомый аргумент, чем сотня упоминаний на только что созданных ноунейм-сайтах. ИИ цитирует тех, кому доверяет.
- Свежесть информации. Для динамических ниш (технологии, финансы, медицина) ИИ всегда старается предоставлять приоритет более новым данным.
- Структура контента. Моделям проще извлекать данные из текста с четкой иерархией, таблицами, списками и готовыми смысловыми кусками.
- Наличие доказательств и фактов. ИИ прекрасно распознает «воду» и пустые маркетинговые лозунги типа «мы самая лучшая компания на рынке». Вместо этого модели предпочитают конкретные цифры, кейсы, технические характеристики.
- Отзывы и рейтинги. Когда пользователь просит ИИ посоветовать лучших, модель проверяет независимые платформы с отзывами, сканирует оценки реальных людей, резюмирует их и на основе этого готовит ответ.
Теперь давайте разберемся, как подготовить контент для продвижения в поиске AI.
Контент на сайте: как писать статьи, которые LLM может процитировать
От теории переходим к практике – как создавать контент, который ИИ с большей вероятностью заметит.
Формируйте последовательную сущность бренда
Чтобы ИИ четко связал название вашей компании с правильными ассоциациями, используйте формулу идеальной сущности бренда:
Бренд + Категория + Позиционирование + Ключевое свойство + Сценарий использования + Доказательство
| Компонент формулы | Что это | Пример |
| Бренд | Уникальное название компании, унифицированное написание во всех источниках | Wascobags |
| Категория | Четкая рыночная ниша или тип продукта | Рюкзаки для путешествий |
| Позиционирование | Стиль, ценовой сегмент или характер бренда | Бюджетные рюкзаки для ручной клади |
| Ключевое свойство | Техническая фишка, материал или главная ценность | Идеально подходят для лоукостеров |
| Сценарий использования | Конкретная жизненная ситуация клиента | Вместительный рюкзак для путешествий лоукостерами, когда не хочется платить за дополнительный багаж |
| Доказательство | Социальное доказательство, цифры, тесты или награды | Размеры четко отвечают требованиям авиакомпаний WizzAir, RyanAir |
Каждая страница сайта должна в унисон повторять эту сущность бренда.
Пишите самодостаточные смысловые блоки
Поскольку ИИ мыслит «кусками» информации, а не страницами, пишите свой контент так, чтобы робот мог легко вырвать любой абзац из контекста и процитировать его в своем ответе. Если мнение чрезмерно растянуто, или чтобы понять его, нужно обязательно прочесть три предыдущих абзаца — ИИ просто проигнорирует этот материал.
Вот главные правила, как создать самодостаточный контент для AI-поиска:
- Один абзац – одна законченная мысль. Пишите емкие, лаконичные определения по принципу «тезис+аргумент+пример». Каждый такой блок должен иметь смысл, даже если читатель не видел остальную статью.
- Используйте списки и маркировку. Нейросети часто берут со страницы структурированные перечни, ведь их проще всего трансформировать в финальный ответ.
- Вводите формат «Вопрос-Ответ». Формулируйте подзаголовки или отдельные блоки прямо в виде вопросов, которые люди задают чат-ботам, например: «Как выбрать безопасное детское автокресло?», и сразу под ними давайте прямой, четкий ответ.

Главный маркер качества для LLM-текста: если вы скопируете один случайный абзац из своей статьи и отправите его другу, он должен полностью понять, о чем идет речь, без дополнительных объяснений. Именно такие «автономные» блоки ИИ забирает в свои ответы охотнее всего.
Используйте правильную структуру H1-H3
Классическую иерархию заголовков (H1, H2, H3) в традиционном SEO используют, чтобы показать работам Google вес ключевых слов и общую тему страницы. Для LLM SEO заголовки играют другую роль — они маркируют намерения (интенты) пользователя и служат для ИИ «дорожной картой» при нарезании текста на смысловые блоки:
- H1 – название статьи. Задает главную тему. ИИ сразу понимает, в какую «папку» в своей памяти отнести эту страницу.
- H2 – основные блоки. Разбивают глобальную тему на большие логические шаги или подтемы.
- H3 – конкретные микро-интенты. Важнейший уровень для ИИ. Именно здесь нужно вписывать точечные запросы, которые люди обычно вбивают в ChatGPT или Perplexity. К примеру, вместо сухого заголовка «Выбор игрушки для собаки» лучше написать H3 «Как выбрать безопасную игрушку для щенка до 6 месяцев».
Правильная структура заголовков помогает ИИ-модели мгновенно сориентироваться, а значит, увеличивает ваши шансы попасть в ответы ChatGPT или другого AI.
Раскрывайте веероподобные запросы
Когда пользователь задает вопросы, ИИ редко ищет ответ только по одной этой фразе. Современные поисковые AI-системы используют технологию Query Fan-Out – это декомпозиция или разветвление запроса. Искусственный интеллект принимает лаконичный запрос пользователя и самостоятельно генерирует на его основе 3–5 дополнительных, более специфических и детализированных поисковых запросов, чтобы собрать максимально полную картину.
Поэтому, когда вы пишете статью на определенную тему, не ограничивайтесь базовым ключевым словом. Всегда разворачивайте интент в глубину:
- Проанализируйте сопутствующие вопросы. Подумайте, какие 4–5 уточняющих вопросов возникнут у человека (и соответственно у ИИ) после прочтения главного тезиса.
- Создавайте подзаголовки под эти вопросы. Прямо в пределах одной статьи дайте краткие, исчерпывающие ответы на все эти разветвленные темы.
Ваша задача – написать такой материал, чтобы когда Query Fan-Out сгенерирует свои пять дополнительных запросов, ИИ нашел ответы на каждый из них в разных абзацах вашей же страницы, и ему не пришлось идти на сайты ваших конкурентов.
Форматируйте контент корректными HTML-тегами
Чтобы облегчить работу алгоритмов ИИ, структурируйте свой контент с помощью HTML-тегов.
Вот элементы форматирования, из которых чат-боты охотнее всего забирают информацию:
- Таблицы. Если вы сравниваете цены, свойства продуктов либо лимиты нагрузки — оформляйте это только таблицей.
- Списки с жирным выделением. Идеально для инструкции. Начинайте каждый пункт с конкретного действия, выделенного жирным: «1. Создайте вебхук. Для этого…». Так нейросеть сразу видит суть каждого шага.
- Формат «Срок – значение». Если на странице есть глоссарий, часто задаваемые вопросы или словарь понятий, используйте четкую структуру списков определений: <dl>, <dt>, <dd>. Это помогает ИИ безошибочно связать термин с его описанием.
- Содержательные ссылки. ИИ оценивает ссылки вместе с текстом вокруг них. Не используйте анкоры типа «здесь» или «по ссылке». Пишите содержательно: «читайте условия акции бренда» или «статья о лучших плагинах для WordPress». Это дает роботу пониманию, куда ведет ссылка.
- Маркировка важной. Выделяйте тегом <strong> ключевые цифры, дедлайны или главные фишки. Во время сбора информации ИИ, прежде всего, обращает внимание на такие семантические акценты в коде страницы.
Мы думали, не добавить ли этот пункт в следующий раздел о технической оптимизации, но HTML-разметка давно стала своеобразной пунктуацией для авторов, поэтому оставим это здесь.
Техническая оптимизация сайта под LLM
Чтобы робот вынул из вашего сайта правильные ответы, ему нужно помочь на уровне кода, тегов и серверной логики.
Доступность сайта для ШИ-краулеров
Чтобы ChatGPT, Gemini или Perplexity процитировали ваш сайт, их роботы должны сначала попасть туда. Любой технический барьер на пути краулера – это гарантированное отсутствие бренда в ответах на ИИ, поскольку модели часто собирают данные в реальном времени.
Что нужно настроить для доступа ИИ:
- Файл robots.txt. Убедитесь, что сайт открыт для главных ИИ-краулеров: GPTBot и ChatGPT-User, PerplexityBot, ClaudeBot, Google-Extended.
- Контроль noindex. Если страница закрыта для Google, она невидима и для ИИ.
- Динамический sitemap.xml. Карта сайта должна обновляться и содержать корректные теги дат (<lastmod>), чтобы ИИ-пауки вовремя находили новый контент.
- Bing Webmaster Tools + Google Search Console. Bing – поисковый движок для ChatGPT Search и Copilot. Если сайта нет в индексе Bing, ChatGPT не найдет его в реальном времени. Добавление sitemap.xml в оба инструмента для вебмастеров – обязательное условие.
Доступность контента в HTML
Весь важный контент должен быть вшит в сырой HTML-код страницы сразу, а не генерироваться «на лету».
Что ломает видимость для ИИ:
- Скрытый контент. Текст, скрытый за кнопками «Показать больше» или интерактивными вкладками, которые подгружаются через JS только после клика мышью.
- Попапа. Любая информация внутри всплывающих окон, активируемых скроллом или временем на странице, закрыта для роботов.
- Client-Side Rendering. Если ваш сайт собирает контент в браузере пользователя с помощью JavaScript, ИИ-боты узнают о нем последними. На рендеринг таких страниц уходит много ресурсов, поэтому ИИ-краулеры откладывают их в долгую очередь. Чтобы ваш контент скорее попадал в выдачу ИИ, используйте серверный рендеринг.
Попытайтесь отключить JavaScript в браузере и проверить сайт. Весь контент, который вы хотите видеть в ответах ChatGPT, должен оставаться полностью доступным для чтения без дополнительных кликов, раскрытий или попапов.
Навигационное здоровье сайта
ИИ-боты имеют жестко ограниченный лимит времени и ресурсов для сканирования одной страницы. Если сайт медленно грузится или запутывает их дублями контента, они идут дальше к конкурентам со более быстрыми страницами.
Критические факторы навигационного здоровья:
- Скорость загрузки. Если сервер долго отвечает, ИИ-краулер не будет ждать. Для SEO под LLM скорость – это не просто фактор ранжирования, это вопрос того, попадете ли вы вообще в ответ.
🔗 Что влияет на скорость загрузки сайта: отвечают специалисты по SEO и хостингу - Корректные теги canonical. ИИ очень чувствителен к дублированию контента. Если на сайте нет четких канонических тегов (<link rel=”canonical” href=”…”>), модель может запутаться, какую именно версию считать первоисточником. Правильный canonical гарантирует, что ИИ заберет в свой индекс нужную страницу и как раз ее поставит в финальную цитату для пользователя.
- Логическая внутренняя перелинковка. ИИ-агенты путешествуют по сайту через контекстные ссылки в тексте. Качественная перелинковка помогает боту связать разные статьи и страницы вашего бренда в один цельный тематический кластер. Когда ИИ видит, что ваши материалы ссылаются друг на друга по смежным темам, он лучше понимает общую экспертизу сайта и может брать ответы на разветвленные запросы с ваших страниц.
Максимально упрощайте вес страниц для роботов и связывайте статьи контекстными ссылками. Чем проще и быстрее путь ИИ-паука от одного вашего тезиса к другому, тем выше вероятность, что именно ваш сайт станет его главным источником для ответа на вопросы.
При покупке на год — скидка 20%
Микроразметка Schema.org
Микроразметка Schema.org защищает модели от галлюцинаций: вместо того, чтобы угадывать по контексту, где цена товара, а где название процессора, ИИ берет готовые факты прямо из кода.
Какие элементы разметки следует использовать:
- Product и Offer. Для карточек товаров. Четко указывайте бренд, точную цену, валюту, наличие и характеристики. ИИ-ассистенты типа ChatGPT считывают эти теги, чтобы мгновенно сравнить ваш товар с конкурентами по запросу пользователя.
- Organization и Brand. Создает цифровой профиль компании. Здесь должно быть прописано официальное название, контакты, логотип и самое главное поле sameAs со ссылками на ваши профили в Википедии, LinkedIn и в авторитетных реестрах.
- Автор и Article. Поисковые алгоритмы, особенно Google AI Overviews, внимательно оценивают экспертность контента. Разметка автора страницы со ссылкой на его профессиональное портфолио или соцсети подтверждает для ИИ, что текст писал живой человек с экспертизой, а не генерировал другой бот.
- FAQPage и Review. Ответы и рейтинги модели считывают в первую очередь, чтобы сформировать блок рекомендаций в чате.
Благодаря Schema.org вы говорите с ИИ на его родном языке — языке чистых структурированных данных, минимизируя риск того, что модель «перепутает» ваши цены или характеристики с чужими.

llms.txt и ai.txt
Чтобы контролировать доступ нейросетей к контенту, разработчики создали два новых файла:
🔎 llms.txt – это экспериментальный текстовый файл, который размещают в корне сайта, чтобы предоставить ИИ-моделям сжатую, очищенную от дизайна «карту» ресурса. В нем вы можете прямо подсказать ИИ-инструментам самые важные страницы, ключевые темы и материалы вашего сайта, которые следует изучить в первую очередь.
🔎 ai.txt – еще один экспериментальный файл, пытающийся выполнять роль «этичного регулятора». Через него владельцы сайтов пытаются прописывать условия: каким именно ИИ-паукам разрешено собирать контент для обучения или live-поиска, а каким доступ закрыт или ограничен.
На момент написания статьи ни один из основных поставщиков крупных языковых моделей официально не ввел llms.txt в свой протокол сканирования:
- OpenAI (ChatGPT): придерживаются robots.txt, официально не используют llms.txt.
- Anthropic (Claude): публикуют свой файл llms.txt, но не сообщали, что их сканеры используют этот стандарт.
- Google (Gemini): используют robots.txt (через User-agent: Google-Extended), ничего не упоминают о поддержке llms.txt.
С файлом ai.txt ситуация еще более скептическая: OpenAI, Google, Anthropic его полностью игнорируют, их ИИ-боты смотрят исключительно в robots.txt. Попытка создать отдельный файл для ИИ провалилась, ведь современные нейросети все равно ищут информацию через классические поисковики.
ИИ-оптимизация за пределами сайта: как работать с внешними упоминаниями и рейтингами
Большие языковые модели не ограничиваются сканированием вашего собственного сайта. Наоборот, чтобы сформировать беспристрастный ответ, ИИ ищет подтверждение вашей экспертности на авторитетных сторонних площадках. Поэтому, чтобы попасть в AI ответы, вы должны активно работать с внешним информационным полем.
Какие внешние источники важны для LLM-продвижения:
| Тип источника | Почему важно | Что оптимизировать |
| Рейтинги и агрегаторы | Часто используется в коммерческих AI-ответах | Место в рейтинге, описание, актуальность, отзывы |
| Обзоры и сравнения | Дают модели готовую структуру выбора | Упоминание бренда рядом с конкурентами |
| Сайты с отзывами | Формируют тональность отзывов о бренде | Рейтинг, свежесть отзывов, ответы компании |
| СМИ и PR | Усиливают авторитет | Единое позиционирование, факты, цитаты |
| Форумы, Reddit, Quora | Дают UGC и реальные сценарии использования | Естественные обсуждения, ответы экспертов |
| Каталоги | Усиливают сущность бренда | Единый нейминг, категория, описание |
| YouTube, подкасты | Мультимодальные источники и текстовые расшифровки | Название бренда, категория, экспертность |
Теперь разберемся с тем, как найти конкретные источники, которые ИИ считает авторитетными и какой контент для них писать.
Как работать с рейтингами, обзорами и подборками
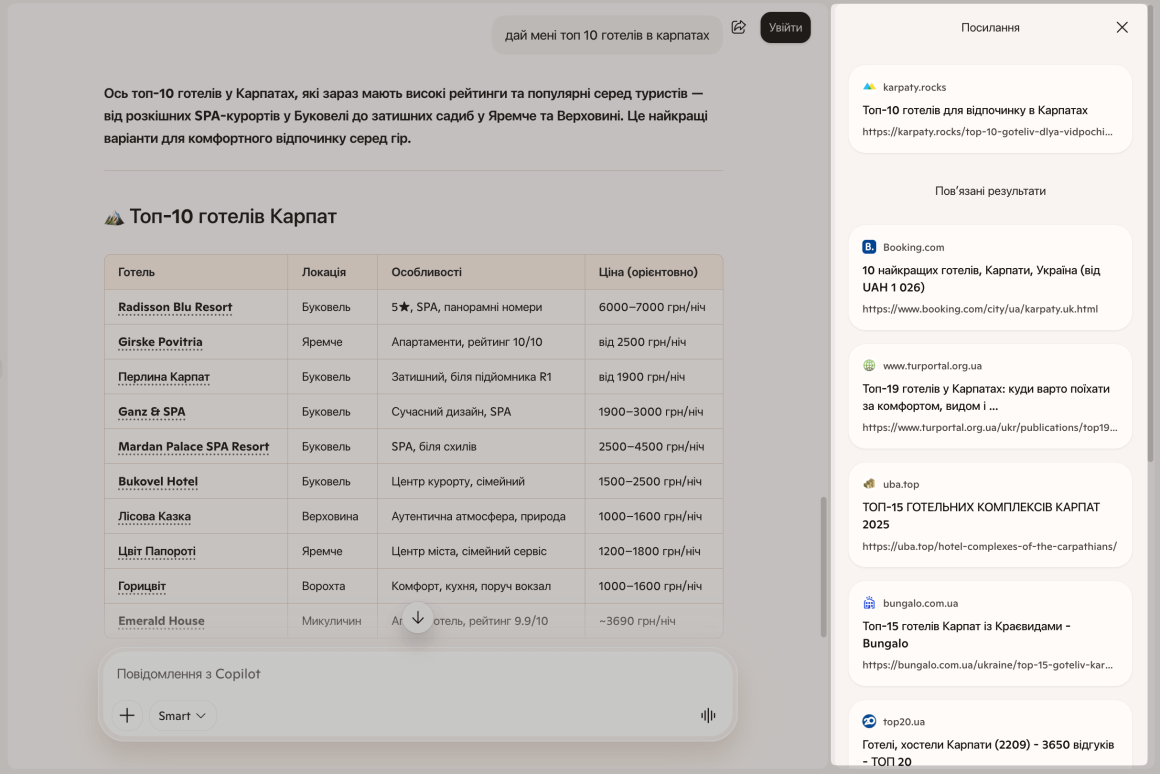
Когда пользователь просит ИИ: «Посоветуй топ-5 лучших CRM для малого бизнеса» или «Какие бренды выпускают качественную анатомическую обувь в Украине?», модель не формирует ответ «из головы». Она мгновенно сканирует свежие подборки, независимые платформы с отзывами и отраслевые рейтинги. Ваша задача – присутствовать на этих страницах-донорах.
Алгоритм действий, чтобы попасть в ИИ-подборки:
- Найдите источники вашего ИИ. Введите в ChatGPT, Perplexity и Gemini ключевые запросы, по которым вы хотите ранжироваться. Посмотрите, какие сайты эти модели открывают и цитируют в первую очередь.
- Постарайтесь попасть в эти тематические подборки. Свяжитесь с редакциями найденных сайтов-доноров. Ваша цель – договориться добавить ваш бренд в их актуальные статьи-рейтинги. Если ИИ привык доверять конкретной статье, появление вашего бренда в ней сделает вас кандидатом на цитирование в чате.
- Работайте с независимыми отзывами платформ. Регулярно обновляйте профили и стимулируйте появление свежих отзывов на площадках типа Google Maps. ИИ анализирует тональность таких отзывов, чтобы сформировать блок «Плюсы и минусы бренда по версии пользователей».
Как писать тексты для гостевых публикаций, чтобы их замечали LLM
Главное правило – ваши гостевые статьи должны нести ценность для читателя (и, соответственно, для ИИ). Пишите экспертные и полезные материалы, наполняйте их уникальными данными, цифрами и кейсами из вашего собственного опыта, ведь ИИ-модели учатся на качественных материалах и просто игнорируют низкопробные рерайты.
При этом оформляйте гостевые лонгриды по тем же техническим правилам, что и свой ресурс: используйте четкие HTML-заголовки <h2>-<h3>, маркированные списки и сравнительные таблицы. Так ИИ-пауку будет максимально легко извлечь и зафиксировать упоминание вашего бренда.
Также не забывайте о последовательности позиционирования бренда:
Бренд + Категория + Позиционирование + Ключевое свойство + Сценарий использования + Доказательство
В общем, статья для внешней площадки должна быть такой же качественной, как и для собственного сайта.
Как отслеживать эффективность продвижения под LLM
Стандартной «позиции в ChatGPT» не существует. Эффективность оценивают в динамике по группам промптов в нескольких чат-ботах с помощью следующих метрик:
| KPI | Что показывает | Как измерить |
| Mention Rate | Доля упоминаний бренда среди всех ответов ИИ в вашей нише | Автоматический треккинг группы промптов через Ahrefs, SE Ranking или специализированные GEO-сервисы |
| Top-3 Rate | Вероятность того, что бренд попадет в первую тройку рекомендаций чат-бота | Мониторинг выдачи по коммерческим промптам через API ИИ-моделей или парсеры |
| Citation Rate | Как часто ИИ ставит кликабельную ссылку на ваш сайт как на первоисточник | Анализ блоков «Источники» и цитат в Perplexity, Gemini и Google AI Overviews |
| Source Overlap | Совпадение вашей базы ссылок с сайтами, которые ИИ чаще всего цитирует по вашим ключевым темам | Сравнение списка топ-доноров с ИИ с вашими текущими обратными ссылками |
| Positioning Match | Насколько тональность и контекст ответа ИИ совпадают с позиционированием бренда | Семантический анализ ответов чат-ботов: анализ сопутствующих LSI-слов и ассоциаций, которые ИИ подбирает к бренду |
| AI-Referral Traffic | Количество реальных пользователей, перешедших на сайт по ссылкам из ИИ-ответов | Google Analytics 4: отчет по переходам, отслеживание источников типа ai.com, perplexity.ai |
| Share of Voice (SOV) / Competitor Share | Ваша доля рынка внутри ИИ-выдачи по сравнению с главными конкурентами | Расчет соотношения упоминаний вашего бренда к упоминаниям конкурентов в пределах одной группы промптов |
Учитывайте, что собирать ИИ статистику вручную неэффективно из-за глубокой персонализации выдачи: чат-боты подстраивают ответы под историю диалогов, локацию и профиль конкретного пользователя. Ваша личная выдача всегда будет искажена.
Чтобы получить объективные данные, используйте сервисы типа AI-модулей в Ahrefs или SE Ranking. Они посылают сотни запросов через API в «чистых» сессиях без сохраненного контекста и с разных IP-адресов, рассчитывая реальную среднюю вероятность появления бренда в ответе ИИ.
Чек-лист: как продвигать сайт под LLM
Напоследок делимся чек-листом, чтобы вы могли быстро проверить готовность сайта и контента к требованиям ИИ-поиска:
- Технический доступ. Сайт полностью открыт в robots.txt для GPTBot, ChatGPT-User, PerplexityBot, ClaudeBot и Google-Extended.
- Индексация. Важные страницы не имеют тега noindex, а динамическая карта sitemap.xml с корректными датами <lastmod> вовремя поступает в Google Search Console и Bing Webmaster Tools.
- Доступность контента. Контент отдается ИИ в готовом виде с первой секунды, а не собирается затем в браузере пользователя. Весь полезный текст, таблицы и списки вшиты в сырой HTML-код и не скрыты за попапами, табами или кнопками «Показать больше».
- Навигационное здоровье. Страницы загружаются мгновенно, настроены четкие метки canonical для защиты от дублей, а статьи связаны плотной контекстной перелинковкой.
- ШИ-файлы. В корень сайта добавлены экспериментальные Markdown-файлы llms.txt и ai.txt в качестве дополнительной подсказки для разработчиков и ИИ-агентов.
- Оптимизация контента. Текст отвечает на конкретные вопросы пользователя, содержит четкие инструкции, списки и FAQ. Интегрирована микроразметка Schema.org.
- Внешние упоминания. Ваш бренд упоминается в отраслевых рейтингах, обзорах и подборках, которые цитирует ИИ.
- Консистентная сущность бренда. На собственных ресурсах и в гостевых публикациях вы постоянно употребляете одни и те же формулировки: Бренд + Категория + Позиционирование + Ключевое свойство + Сценарий + Доказательство.
- Аналитика. Настроен автоматический мониторинг упоминаний в ИИ: через сервисы Ahrefs или SE Ranking отслеживается, как часто чат-боты рекомендуют бренд, попадает ли он в топ-3 результатов и сколько реальных переходов на сайт это приносит.
На этом все. Как вы могли понять из статьи, продвижение под ИИ – это не замена классическому SEO, а мощная надстройка, объединяющая техническую оптимизацию, контент-маркетинг и управление репутацией бренда. ИИ-модели не создают информацию с нуля, они только анализируют и обобщают уже имеющийся в сети контент.
Чтобы искусственный интеллект рекомендовал именно ваш бренд, он должен регулярно видеть упоминания о нем на авторитетных площадках, в структурированном виде и правильном контексте. Только сильное и комплексное присутствие бренда в интернете увеличивает ваши шансы попасть в ответы ИИ .




