
Веб-архив сайтов или Web Archive — это сервис, который собирает и хранит копии сайтов. Это своего рода машина времени интернета, которая позволяет отследить развитие веб-ресурса с начала его создания, просмотреть уже несуществующий сайт, а также восстановить его даже при отсутствии резервной копии.
В этой статье вы найдете обзор базовых возможностей веб-архива сайтов и детальные инструкции по использованию сервиса.
Что такое Web Archive и зачем он нужен
Архив интернета — это некоммерческая библиотека книг, программного обеспечения, сайтов, аудио- и видеозаписей. Наиболее популярный проект — Wayback Machine, также известный как веб-архив сайтов.
Это бесплатный сервис, где собраны архивные копии веб-ресурсов за разные даты. Копии появляются при сохранении вручную, а также когда веб-краулеры посещают сайт.
Веб-краулер, он же паук или бот — это программа, которая посещает сайты, оценивает содержимое, а затем переносит их в базу поисковых систем или веб-архива, как в нашем случае.
С помощью интернет-архива можно узнать, как выглядел сайт раньше: месяц или несколько лет назад.

Именно это и было изначальной целью проекта. Однако за последнее время функций у машины времени сайтов стало больше.
Веб-архив сайтов используют, чтобы:
- просмотреть, как сайт выглядел раньше;
- восстановить сайт, даже если у вас нет резервной копии;
- проанализировать изменения ресурса в определенный период;
- найти уникальную информацию, которую удалили;
- проверить репутацию доменного имени перед регистрацией — если ранее его использовали для размещения сомнительного контента, могут возникнуть трудности и сейчас.
Статья по теме:

Как пользоваться веб-архивом
Интерфейс веб-архива сайтов интуитивный в использовании.
Перейдите на страницу машины времени сайтов, укажите URL-адрес и нажмите «BROWSE HISTORY»:
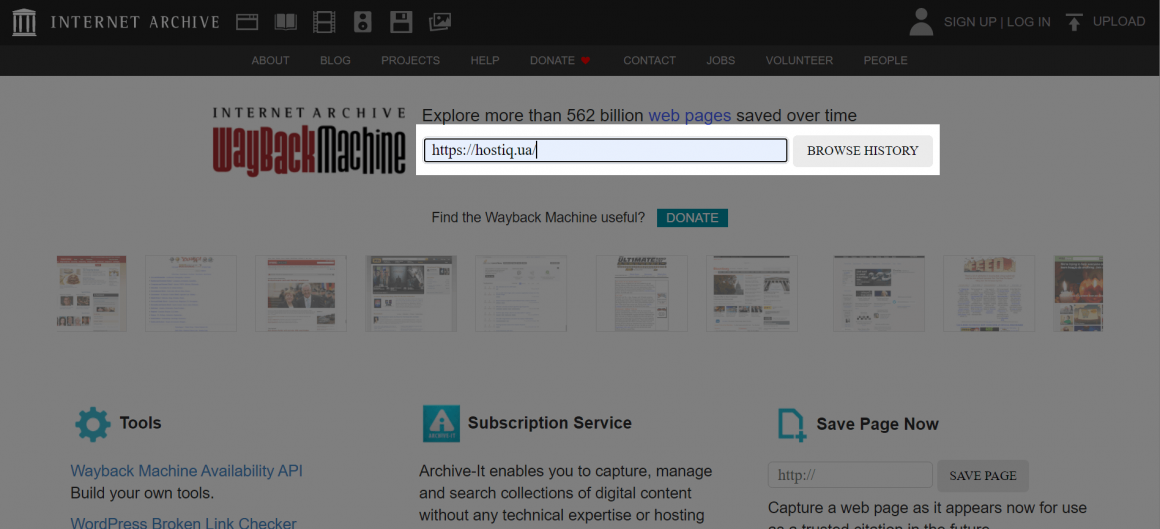
По умолчанию веб-архив подгружает секцию «Calendar», где можно посмотреть старые версии нужного сайта:
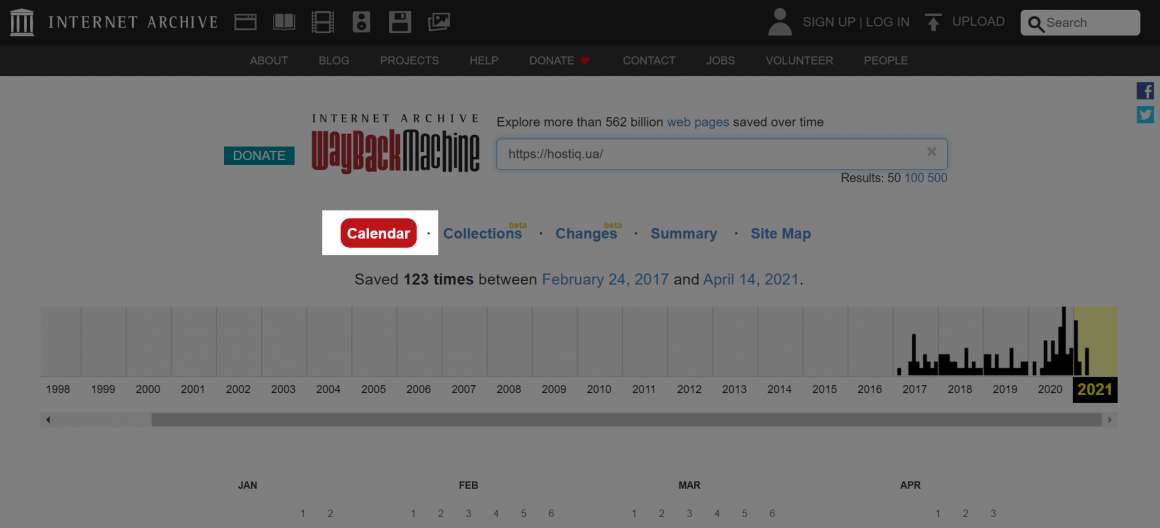
После обработки запроса вы сразу же увидите общую информацию о веб-странице: количество сгенерированных архивов и шкалу времени, начиная с первой копии по текущий момент:
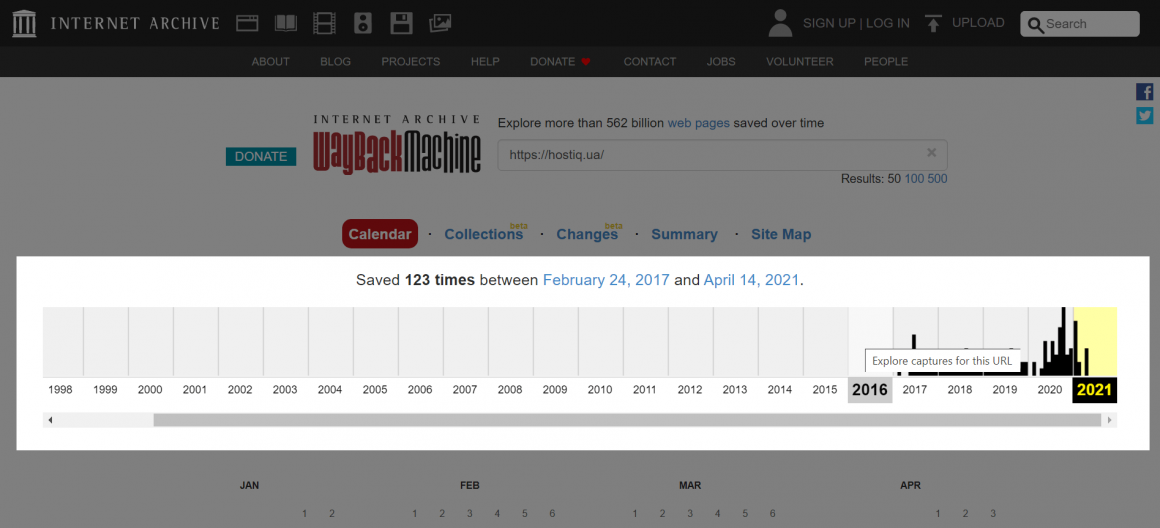
Выберите год на шкале времени. Ниже вы увидите календарь, где цветными маркерами обозначены даты, когда веб-краулеры интернет-архива сканировали страницу:
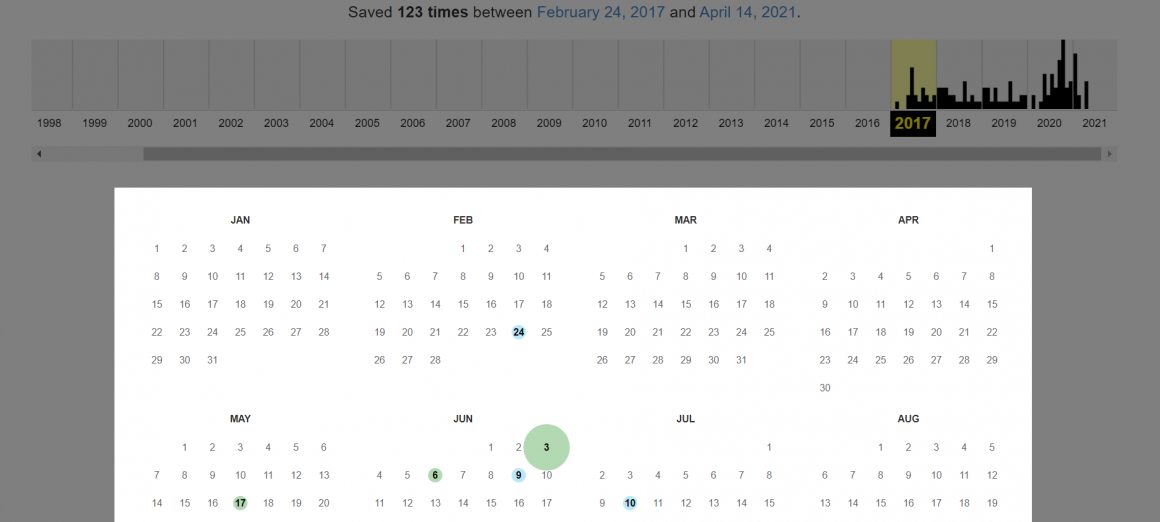
Маркеры отмечены одним из четырех цветов:
- Синий значит, что веб-краулер получил в ответ код со статусом 200 OK, то есть сайт стабильно работал.
- Зеленый соответствует коду 3хх — в тот момент создания копии на сайте был настроен редирект.
- Оранжевый и красный цвета значат, что веб-ресурс был недоступен, и веб-краулер получил код ошибки 4хх и 5хх.
Диаметр круга зависит от количества обращений робота веб-архива к странице в этот день. Чем больше круг, тем больше копий за этот день создал веб-краулер.
Попробуйте хостинг с кучей плюшек: автоустановщиком 330 движков, конструктором сайтов и теплой поддержкой 24/7!

Выбрав дату, наведите курсор на нее и нажмите на время сохранения:
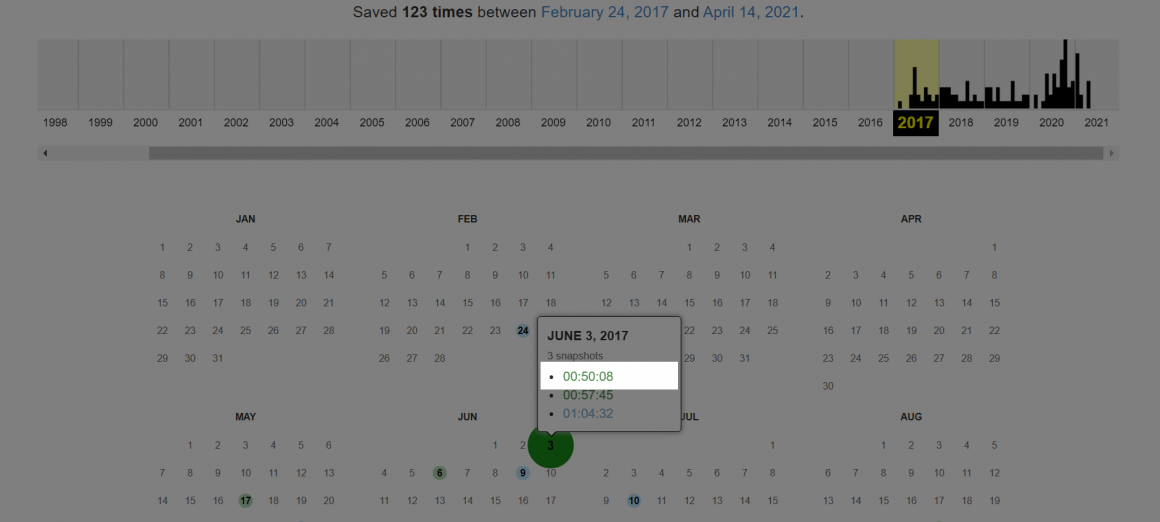
Вы увидите желаемую версию веб-страницы.
Бывают ситуации, когда в интернет-архиве нет старых версий ресурса: правообладатель потребовал удалить принадлежащий ему контент или сайт закрыт из-за нарушения закона о защите интеллектуальной собственности. Дополнительно, на сайте могут быть настройки, которые ограничивают работу веб-краулеров. Таким образом, боты его не сканируют.
Иногда нужный ресурс доступен, но в копии нет картинок или части контента. Это происходит, если сайт был не полностью заархивирован Wayback Machine. В таком случае попробуйте открыть версию сайта за другой день.
Дополнительную информацию о сайте можно найти в секциях «Summary» и «Site Map»:
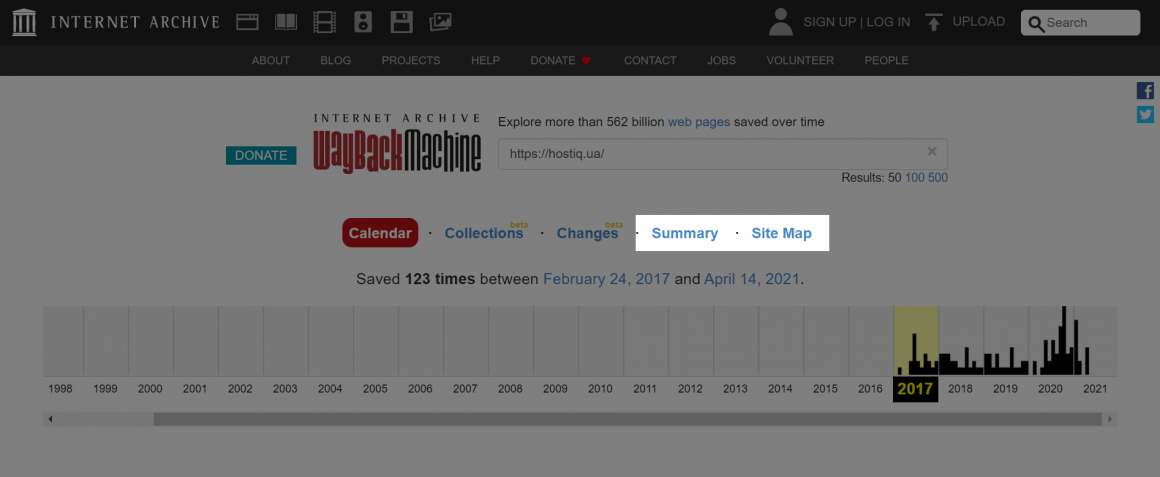
В секции «Summary» собрана статистика по типу файлов, например HTML, CSS, PNG, на вашем сайте.
Функционал секции «Site Map» группирует все архивы нужного ресурса по годам, а затем строит визуальную карту сайта — радиальную диаграмму. Центральный круг — это «корень» сайта, его главная страница. Следующие кольца — остальные страницы. При наведении курсора на кольца и ячейки обратите внимание, что URL-адреса вверху меняются. Вы можете выбрать страницу, чтобы перейти к архиву этого URL-адреса.
Чтобы выявить и отобразить изменения в содержимом архивов, используйте секцию «Changes»:
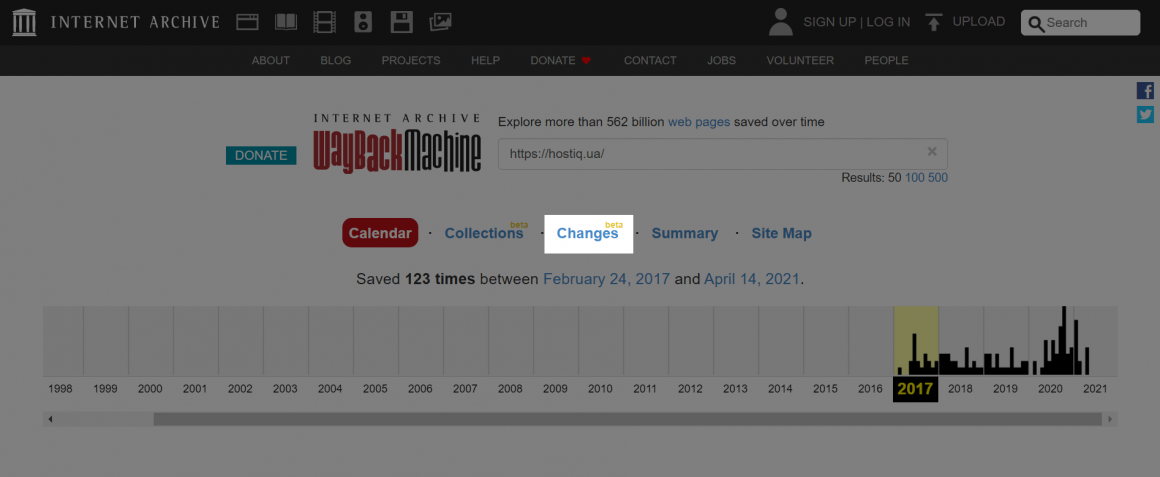
Выберите две даты и нажмите кнопку «Compare»:
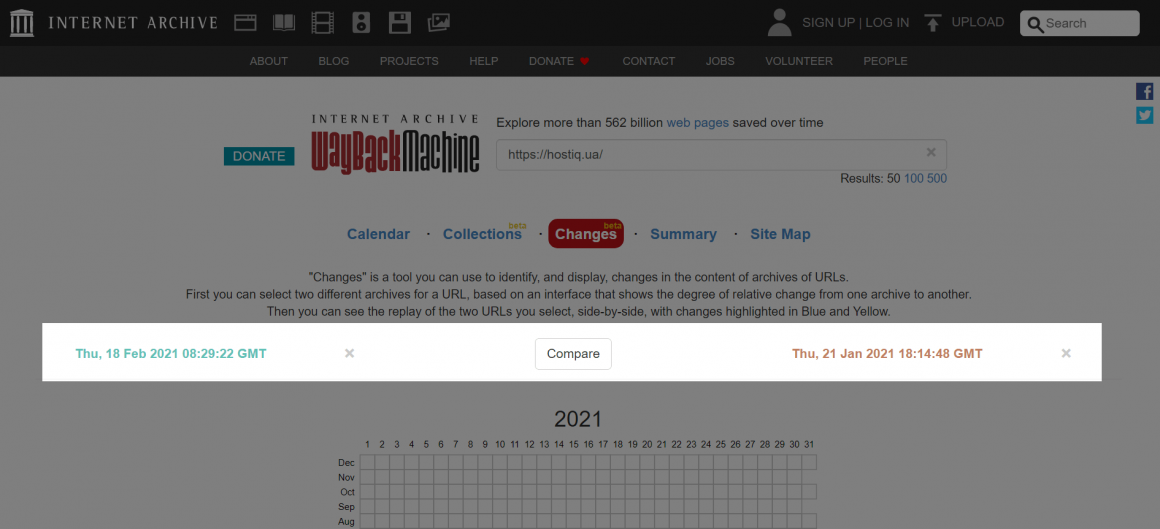
На новой странице появятся две версии сайта. Удаленный контент окрашен в желтый цвет. Синий указывает на добавление содержимого.
Как сохранить текущую версию сайта в веб-архиве
Копии сайтов попадают в веб-архив благодаря веб-краулерам, которые их сканируют. Однако это не единственный способ. Просканировать сайт можно самостоятельно.
Чтобы создать копию одного URL-адреса, найдите опцию «Save page now» на главной странице Wayback Machine, введите ссылку и нажмите «Save page»:
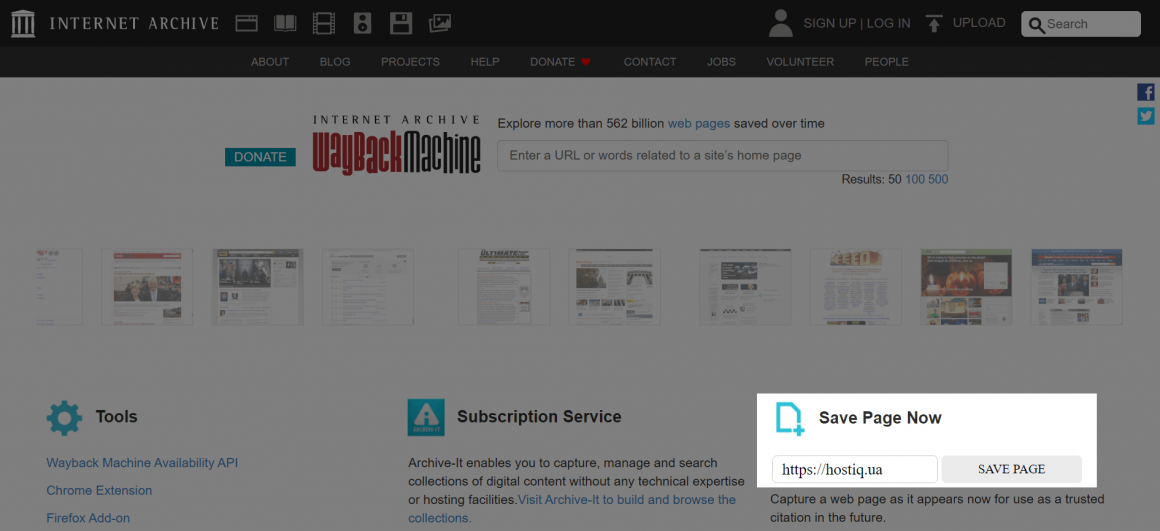
Таким образом, в веб-архив сайтов добавится текущая версия заданного URL-адреса.
Повторяйте это действие перед важными изменениями на сайте и после них. В случае поломки или утери данных вы всегда сможете восстановить сайт через веб-архив.
Создавать копию всего сайта постранично трудоемко. Интернет-архив предоставляет платный сервис, который архивирует сайт в несколько кликов — Archive It.
Статья по теме:

Как запретить добавление сайта в веб-архив
Запретите добавление веб-ресурса в Wayback Machine, если вы:
- дорожите уникальностью контента и не хотите, чтобы его использовали даже после удаления сайта;
- планируете продать доменное имя и не хотите, чтобы ваш контент ассоциировался с новым владельцем;
- хотите удалить личную информацию из открытого доступа.
Запретить добавление сайта в архив интернета можно двумя способами:
- обратиться в поддержку веб-архива;
- использовать файл robots.txt.
Если вы обратитесь в поддержку, вся существующая информация о сайте будет удалена из архива интернета. Дополнительно, веб-краулеры не будут сканировать сайт в будущем.
Чтобы запросить полное удаление вашего сайта из веб-архива, напишите на адрес info@archive.org, указав доменное имя в тексте сообщения.
Файл robots.txt позволяет лишь заблокировать доступ для веб-краулеров. После этого они не будут сканировать сайт, и информация о нем не попадет в архив интернета. Но весь предыдущий материал будет доступен в Wayback Machine. То есть пользователи смогут посмотреть, как сайт выглядел раньше.
Для запрета доступа добавьте в файл robots.txt директиву:
User-agent: ia_archiver
Disallow: /
User-agent: ia_archiver-web.archive.org
Disallow: /
Важно, чтобы файл robots.txt был в корневом каталоге для вашего домена.
Также веб-краулеры не посещают сайты, которые защищены паролем.
Как восстановить сайт из веб-архива
Если сайт был утерян или взломан, а резервной копии нет, попробуйте восстановить контент с Wayback Machine. Вот несколько вариантов, как это можно сделать:
- скопировать контент вручную;
- скопировать контент с помощью скрипта;
- обратиться к сторонним службам.
Первый способ лучше использовать, если вам нужна копия всего одной или нескольких страниц. Второй и третий подойдет тем, кто хочет скопировать контент всего сайта.
Последние два варианта — это использование сторонних инструментов. Мы слышали об этих скриптах и сервисах хорошие отзывы, но не можем гарантировать качество их работы. Советуем всегда создавать резервную копию вручную через панель управления хостингом или использовать хостинг с автоматическими бэкапами.
Пробуйте надежный хостинг с автоматическими бэкапами и аптаймом 99,9%!
Наша теплая поддержка на связи 24/7

Скопируйте контент вручную
У веб-архива сайтов нет услуг по хранению резервных копий и восстановлению работы веб-ресурсов. Потому встроенного функционала, который позволит в несколько кликов получить архив всего сайта, нет. Однако вы можете вручную скопировать текст и код страниц, а также сохранить картинки.
Чтобы скопировать код страницы, перейдите на нее в Wayback Machine, кликните правой кнопкой мыши и выберите «View page source». Скопируйте код и вставьте его в текстовый редактор, где вы можете сохранить его как HTML-файл.
Скопируйте контент с помощью скрипта
Восстановление каждой отдельной HTML-страницы проекта слишком трудоемко, поэтому вы можете использовать специальные скрипты. Они позволяют извлечь все содержимое сайта за один раз.
Некоторые из наиболее популярных вариантов:
Обратитесь к сторонним службам
Существует множество сторонних служб, которые помогают с восстановлением сайта из веб-архива. Цены за услуги будут отличаться в зависимости от объема сайта.
Однако большинство служб дают протестировать их работу бесплатно.
Пара служб, которые могут помочь с восстановлением сайта:
Что запомнить о веб-архиве
- Интернет-архив сайтов — бесплатный проект, цель которого сохранить весь размещенный в интернете контент.
- Наиболее популярный инструмент проекта — Wayback Machine. Это своеобразная машина времени, которая позволяет посмотреть, как сайт выглядел раньше.
- Веб-архив полезен для анализа сайтов, отслеживания изменений и составления статистики, проверки доменов перед покупкой.
- Веб-архив — это запасной вариант по восстановлению сайта при отсутствии резервной копии.
Нужен сайт?
Сделать сайт самому для бизнеса или хобби с нашими готовыми решениями легко как раз-два-три. Бесплатный тест 30 дней!





