В більшості випадків пошукові боти починають свою роботу на сайті з файлу robots.txt. Подібно до дорожнього вказівника, він вказує, куди боти можуть ходити на вашому сайті, а куди їм ходити не слід. Тож якщо цей файл налаштований неправильно, ранжування вашого сайту в пошукових системах може піти шкереберть. Щоб цього не сталося, в цій статті розглянемо, як працює robots.txt для WordPress та як налаштувати robots.txt WordPress-сайту.

Ця стаття — вільний та доповнений переклад матеріалу WordPress Robots.txt Guide: What It Is and How to Use It, що вийшов в блозі Kinsta 🔗
Що таке WordPress-файл robots.txt
Перш ніж будемо говорити про файл robots.txt WordPress, давайте визначимо, що таке «робот» в цьому випадку.
🔎 Роботи — це будь-який тип ботів, які відвідують вебсайти в інтернеті. Найпоширенішим прикладом є пошукові роботи. Ці боти «повзають» по інтернету, щоб допомогти пошуковим системам на кшталт Google індексувати та ранжувати мільярди сторінок в мережі.
Тож боти — це, загалом, добре для інтернету. Або, принаймні, необхідно. Але це не обов’язково означає, що ви або інші власники сайтів хочете, щоб боти бігали безперешкодно.
Бажання контролювати, як веброботи взаємодіють з сайтами, призвело до винайдення файлу robots.txt. Robots.txt дозволяє регулювати те, як «слухняні» боти взаємодіють з вашим сайтом. З його допомогою ви можете повністю заблокувати ботів, обмежити їхній доступ до певних частин вашого сайту тощо.
Однак, слово «слухняні» є важливим. Robots.txt не може змусити бота слідувати своїм директивам. Шкідливі боти можуть і будуть ігнорувати файл robots.txt. Крім того, навіть поважні організації ігнорують деякі команди, які ви можете вказати в robots.txt.
Наприклад, Google проігнорує будь-які правила щодо частоти відвідування сайту його пошуковими роботами, які ви додасте до robots.txt. Ви можете налаштувати швидкість, з якою Google сканує ваш сайт, на сторінці налаштувань швидкості сканування для вашого сайта в Google Search Console.
Тож якщо у вас багато проблем з ботами, окрім robots.txt вам варто використовувати такі рішення, як Cloudflare та Sucuri. Вони можуть захистити ваш сайт як від недобросовісних ботів, так і від різноманітних атак, перевіряючи та фільтруючи трафік, що надходить на ваш сайт.
🔗 Посібник з налаштування Cloudflare
Та якщо ви не маєте клопоту з ботами і просто хочете базово налаштувати доступ до сайту — продовжуйте читати, ця стаття відповість на ваші питання.
Швидко, просто, без програмування!
Коли слід використовувати файл robots.txt
Для більшості власників сайтів у добре структурованого файлу robots.txt є дві основні переваги:
- Пошукові системи швидше обходять ваш сайт, не витрачаючи час на сторінки, які ви не хочете, щоб знаходили. Це допомагає ботам зосередитися на тому, що для вас важливе.
- Ви економите ресурси сервера, заблокувавши небажаних ботів, які марно використовують його потужності.
Також враховуйте, що robots.txt не є надійним способом контролювати, які сторінки індексуються пошуковими системами. Якщо ваша основна мета — не допустити, щоб певні сторінки потрапили до результатів пошуку, правильним підходом буде використати правило noindex або захистити сторінку паролем.
Це пов’язано з тим, що файл robots.txt не забороняє пошуковим системам індексувати вміст — він лише забороняє їм сканувати його. Сам Google попереджає, що якщо зовнішній сайт чи інша сторінка вашого сайту посилається на сторінку, яку ви виключили з індексу за допомогою файлу robots.txt, Google все одно може проіндексувати цю сторінку.
Джон Мюллер, аналітик Google Webmaster Analyst, також підтвердив, що якщо на сторінку є посилання, навіть якщо вона заблокована файлом robots.txt, вона все одно може бути проіндексована. Нижче ми наводимо, що він казав на форумі Webmaster Central:
«Тут варто пам’ятати, що якщо ці сторінки заблоковані robots.txt, то теоретично може статися так, що хтось випадково посилається на одну з цих сторінок. І якщо це станеться, ми можемо проіндексуємо цю URL-адресу без будь-якого контенту, тому що той заблокований файлом robots.txt. Таким чином, ми не будемо знати, що ви не хочете, щоб ці сторінки були проіндексовані.
Якщо ж вони не заблоковані файлом robots.txt, ви можете поставити правило noindex на цих сторінках. І якщо хтось розмістить на них посилання, а ми перейдемо за цим посиланням і подумаємо, що тут є щось корисне, то ми знатимемо, що ці сторінки не потрібно індексувати, і зможемо просто пропустити їх повністю.
Тому, якщо на сторінках є щось, що ви не хочете, щоб було проіндексовано, не закривайте їх через robots.txt, а використовуйте noindex.»
Чи потрібен мені файл robots.txt
Вам не обов’язково мати файл robots.txt на вашому сайті. Якщо ви не проти того, що всі боти можуть вільно сканувати всі ваші сторінки, ви можете не додавати його, оскільки у вас немає ніяких реальних інструкцій для роботів.
У деяких випадках ви навіть не зможете додати файл robots.txt через обмеження CMS, яку ви використовуєте. Це не страшно, адже існують інші способи вказати ботам, як сканувати ваші сторінки, не використовуючи файл robots.txt.
Який код статусу HTTP повинен повертатися для файлу robots.txt
Файл robots.txt повинен повертати код статусу HTTP 200 OK, щоб пошукові роботи могли отримати до нього доступ.
🔗 Що таке коди стану HTTP та як їх перевіряти
Якщо у вас виникли проблеми з індексацією ваших сторінок пошуковими системами, варто двічі перевірити код статусу, який повертається для вашого файлу robots.txt. Будь-який інший код статусу, окрім 200, може перешкодити роботам отримати доступ до вашого сайту.
Деякі власники сайтів повідомляли, що їхні сторінки були видалені з індексу через те, що файл robots.txt повертав статус, відмінний від 200. Власник вебсайту запитав про проблему індексації в Google SEO Office Hours в березні 2022 року, і Джон Мюллер пояснив, що файл robots.txt повинен повертати або статус 200, якщо він присутній, або статус 4XX, якщо файл не існує. У цьому випадку поверталася внутрішня помилка сервера 500, що, за словами Мюллера, могло призвести до того, що Googlebot виключив сайт з індексації.
Те ж саме можна побачити в цьому твіті, де власник сайту повідомив, що весь його сайт було деіндексовано через те, що файл robots.txt повертав помилку 500.
Чи можна використовувати метатег robots замість файлу robots.txt
Ні. Метатег robots дозволяє вам контролювати, які сторінки індексуються, а файл robots.txt дозволяє контролювати, які сторінки скануються. Боти повинні спочатку просканувати сторінки, щоб побачити правила в них. Тому не варто одночасно використовувати правила disallow і noindex, оскільки noindex не буде прийнятий до уваги.
Якщо ваша мета — виключити сторінку з пошукових систем, директива noindex зазвичай є найкращим варіантом.
Стаття з теми:

Як знайти robots.txt на сайті
Зазвичай, WordPress-сайт «з коробки» не має фізичного файлу robots.txt, який ви могли б редагувати, проте движок сам створює віртуальний варіант з набором базових правил. Також багато SEO-плагінів або плагінів для керування сайтом можуть створювати стандартний robots.txt для WordPress автоматично, як частину свого функціоналу. Тому варто для початку перевірити, чи у вас вже є цей файл.
Де знаходиться файл robots.txt:
Файл robots.txt знаходиться в корені вашого сайту, тому щоб його побачити (якщо він у вас є), додайте /robots.txt після вашого домену. Наприклад, https:/hostiq.ua/robots.txt.
Якщо за посиланням https:/your-domain/robots.txt ви бачите записи, але в кореневому каталозі вашого сайта на хостингу файлу з назвою «robots.txt» нема — ви маєте тільки віртуальний robots.txt.
Щоб відредагувати записи чи додати нові — читайте наш наступний розділ.
Як створити та редагувати файл robots.txt у WordPress
Перед вами приклад robots.txt для WordPress, який генерує сам движок.
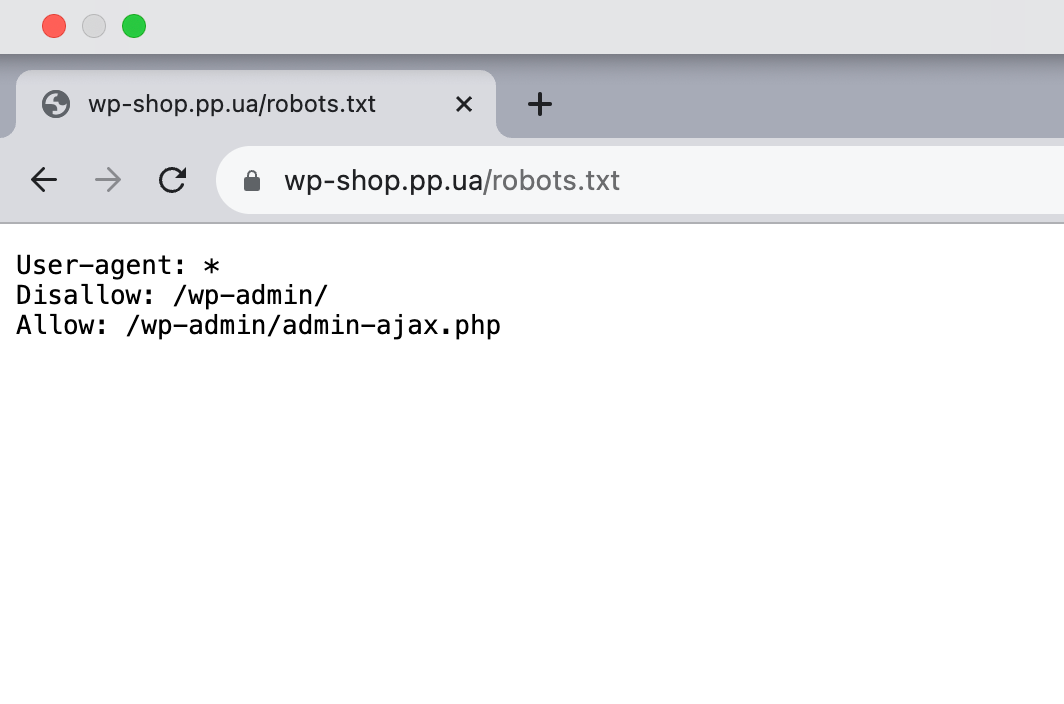
В ньому всього три рядка зі стандартними інструкціями для всіх роботів: проходити повз адмінпанель WordPress, тобто каталог /wp-admin/, але заходити в файл /wp-admin/admin-ajax.php.
Як ми казали в попередньому розділі, стандартний robots.txt для WordPress є віртуальним, ви не можете його редагувати. Якщо ви хочете відредагувати файл robots.txt, потрібно створити фізичний файл на вашому сервері, з яким ви зможете працювати за потреби.
Ось три простих способи зробити це:
- створити та редагувати файл robots.txt в WordPress за допомогою плагіна Yoast SEO;
- створити та редагувати файл robots.txt за допомогою плагіна All in One SEO;
- створити та редагувати файл robots.txt через FTP.
Розберемося в кожному з них детальніше.
Як створити файл robots.txt для WordPress за допомогою Yoast SEO
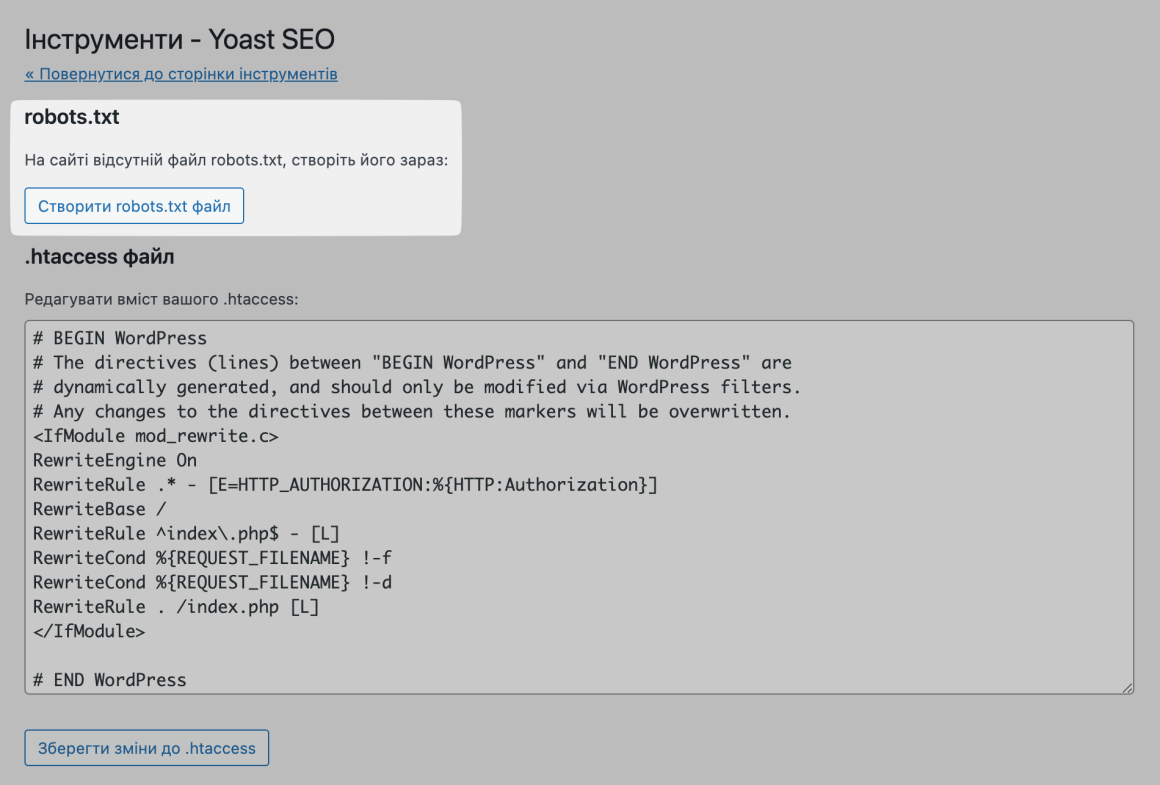
Якщо ви використовуєте популярний плагін Yoast SEO, ви можете створити та відредагувати файл robots.txt прямо з інтерфейсу Yoast. Для цього перейдіть в меню ліворуч в розділ Yoast SEO → Інструменти і натисніть на Редактор файлів.
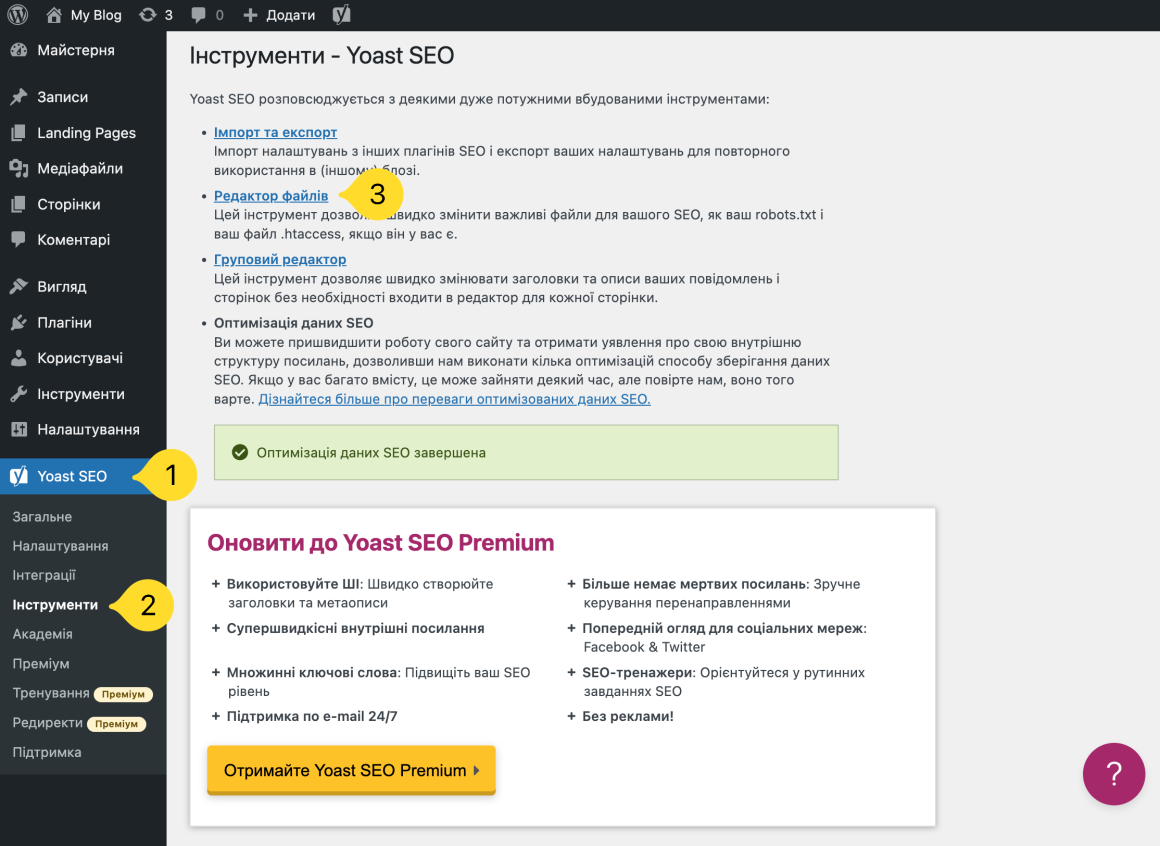
Якщо файл robots.txt вже створено, ви одразу зможете його відредагувати.
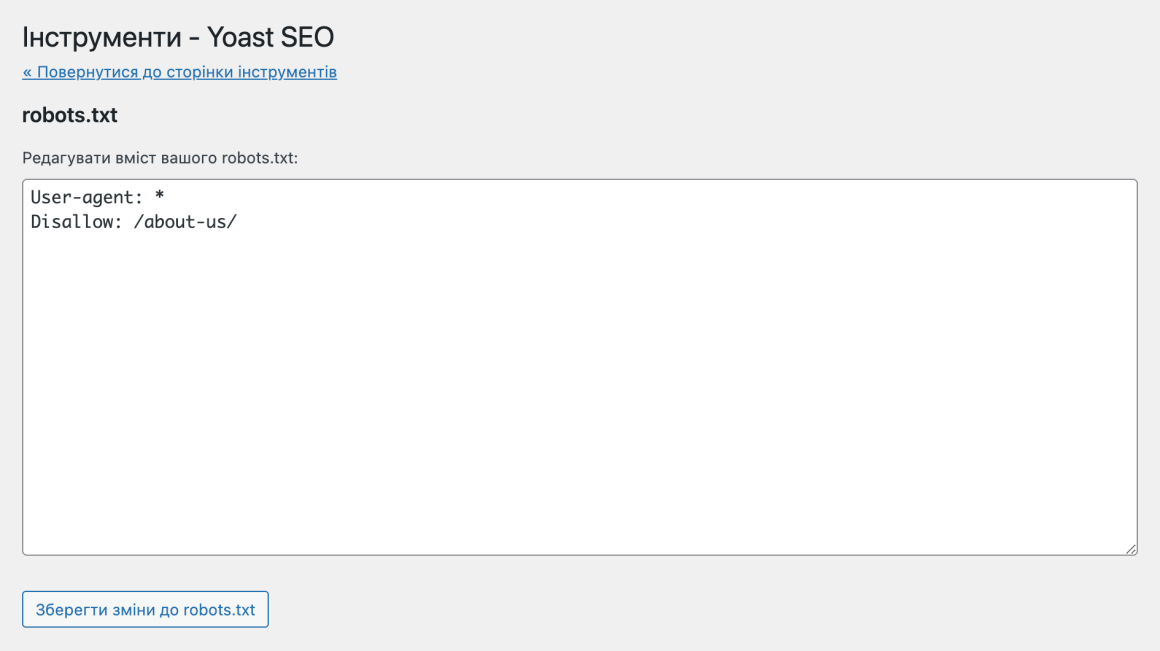
Якщо у вас ще немає фізичного файлу, Yoast запропонує вам створити файл robots.txt:
🔗 Детальніше про створення robots.txt з Yoast SEO
Якщо ви цікавитеся пошуковою оптимізацією свого сайту, вам варто знати і про це 👇
Google враховує швидкість сайту під час ранжування
Швидкість сайту впливає на те, як відвідувач сприймає сторінки, тому з 2018 року вона стала однією з метрик, яку Google враховує при ранжуванні. Якщо відвідувач не дочекався, поки завантажиться сторінка, та закрив вкладку, це мінус у карму та рейтинг пошукової видачі.
Подбайте про швидкість свого сайту — розмістіть його на хостингу із чистими SSD-дисками 🚀
Ми відмовилися від HDD-дисків на серверах та перейшли на SSD. На SSD-дисках сайти завантажуються вп’ятеро швидше, ніж на HDD.
Також ми замінили вебсервер Apache на LiteSpeed, щоб збільшити швидкість роботи сайтів. За статистикою, на LiteSpeed файли відкриваються в 5 разів швидше. А якщо ваш сайт на WordPress, то ми прискоримо його ще більше з плагіном LSCache.
Наш хостинг можна безплатно тестувати протягом 30 днів. Переконайтеся, що ваш сайт працює з нами швидше — і тоді вже прийматимете рішення щодо купівлі 🔥
Як редагувати robots.txt WordPress-сайту за допомогою All in One SEO
Якщо ви використовуєте інший популярний SEO-плагін All in One SEO Pack, він самостійно створює файл robots.txt зі стандартними для WordPress налаштуваннями. Також ви можете додавати власні правила та редагувати файл robots.txt прямо з інтерфейсу плагіна.
Все, що вам потрібно зробити, це перейти в розділ All in One SEO → Інструменти та знайти перемикач Увімкнути користувацький Robots.txt.
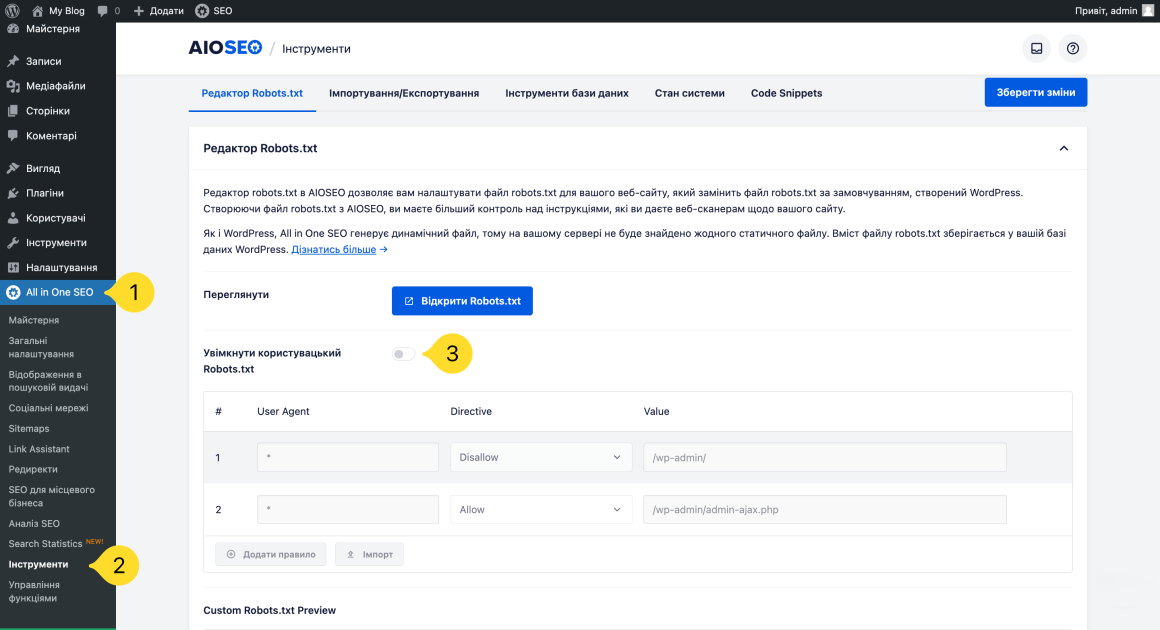
Переведіть перемикач в увімкнене положення. В рядках нижче ви зможете створювати власні правила та додавати їх до файлу robots.txt.
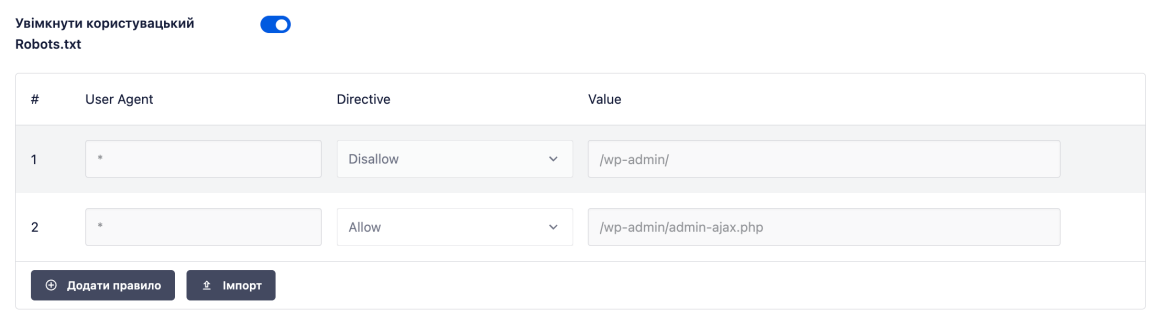
Не забудьте натиснути кнопку Зберегти зміни в правому верхньому або нижньому кутку.
🔗 Детальніше про створення robots.txt з All in One SEO
Як створити та редагувати файл robots.txt через FTP
Якщо ви не використовуєте жоден SEO-плагін, який би дозволяв створювати та редагувати robots.txt в адмінпанелі, ви можете створити файл і керувати ним через FTP чи панель керування хостингом.
За допомогою будь-якого текстового редактора створіть порожній файл з ім’ям «robots.txt», потім підключіться до свого сайту через SFTP і завантажте цей файл до кореневої папки вашого сайту. Ви можете вносити подальші зміни до файлу robots.txt, редагуючи його через SFTP або завантажуючи нові версії файлу.
Інший варіант, створити та редагувати файл через панель керування хостингом. Ми використовуємо на нашому віртуальному хостингу панель cPanel. Щоб створити файл в ній, перейдіть в розділ Диспетчер файлів.
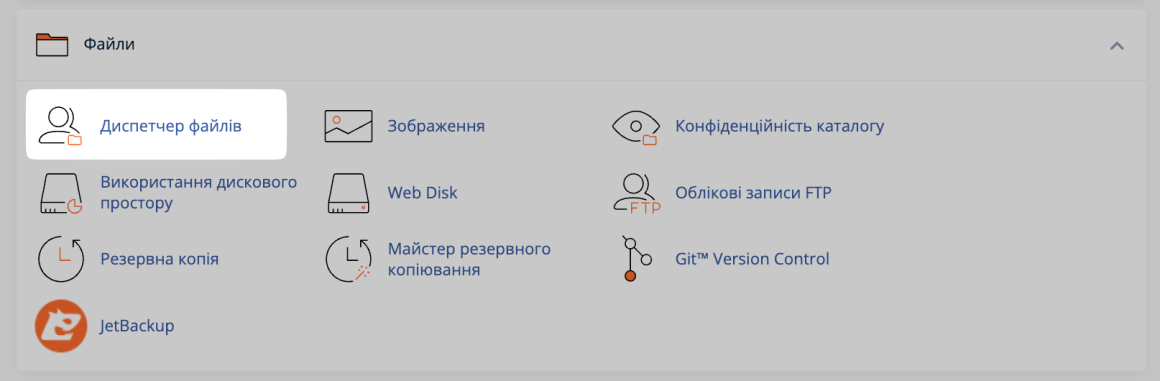
Увійдіть в папку вашого домену та натисніть + Файл вгорі. Назвіть файл «robots.txt» та натисніть Create New File.
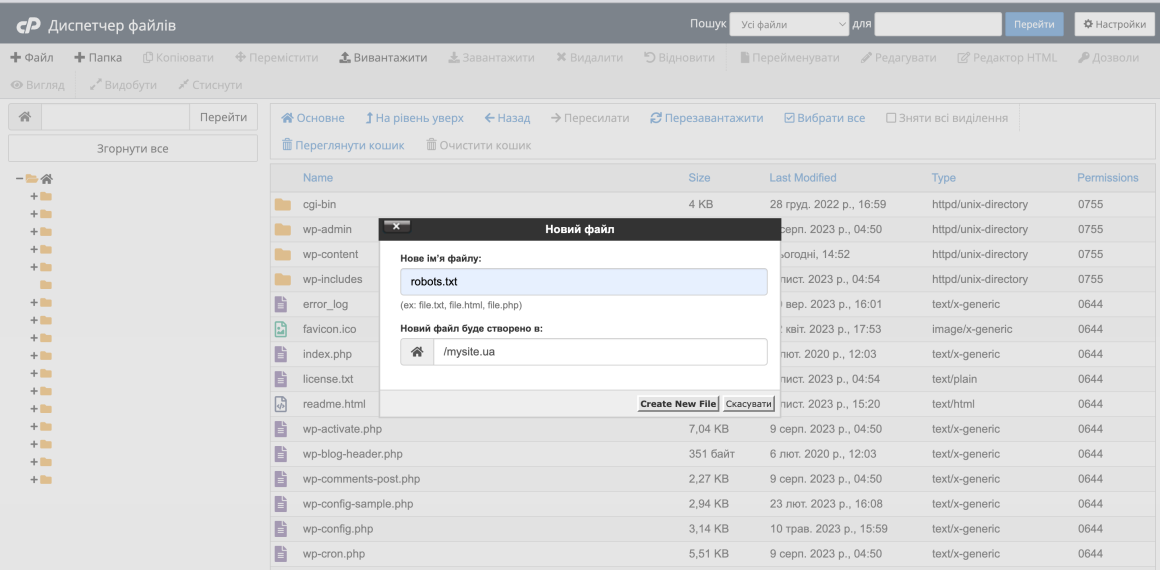
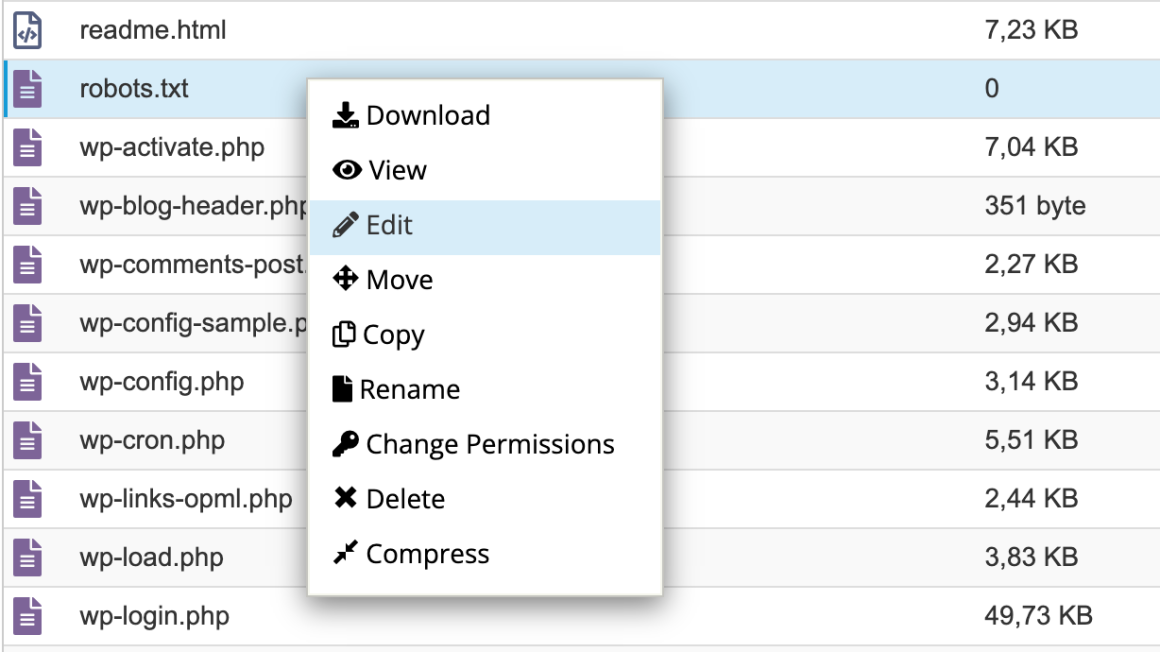
Щоб внести записи в файл, натисніть на нього правою кнопкою миші та виберіть Edit і ще раз Edit.
Що потрібно додати до файлу robots.txt
Тепер на вашому сервері є фізичний файл robots.txt, який ви можете редагувати за потреби. Давайте розбиратися, що ж в ньому писати на практиці.
Як ми писали в першому розділі, robots.txt дозволяє контролювати взаємодію роботів з вашим сайтом. Ви робите це за допомогою двох основних команд:
- User-agent — дозволяє націлюватись на конкретних ботів. Користувацькі агенти — це те, що боти використовують для ідентифікації. З їх допомогою ви можете, наприклад, створити правило, яке застосовуватиметься до Bing, але не до Google.
- Disallow — дозволяє заборонити роботам доступ до певних частин вашого сайту.
Існує також команда Allow, яку ви можете використовувати в нішевих ситуаціях. За замовчуванням, все на вашому сайті позначено Allow, тому в 99% ситуацій в цій команді немає необхідності. Але вона стане в пригоді, якщо ви хочете заборонити доступ до папки та її дочірніх папок, але дозволити доступ до однієї конкретної дочірньої папки чи файлу.
Ви додаєте записи в robots.txt в такому порядку:
- до якого User-agent має застосовуватися правило,
- які саме правила слід застосувати за допомогою команд Disallow і Allow.
Існують також деякі інші команди, такі як Crawl-delay і Sitemap, але вони:
- або ігноруються більшістю основних пошукових систем чи інтерпретуються дуже по-різному (у випадку затримки сканування, Crawl-delay);
- або стали непотрібними за рахунок таких інструментів, як Google Search Console (для карт сайту, Sitemap).
Давайте розглянемо конкретні випадки використання, як все це поєднується.
Стаття з теми:

Як використовувати Disallow в файлі robots.txt для блокування доступу до всього сайту
Припустимо, ви хочете заблокувати доступ до вашого сайту для всіх пошукових роботів. Це навряд чи станеться на «живому» сайті, але це може стати в пригоді для сайту на стадії розробки. Для цього потрібно додати до вашого файлу robots.txt такий Disallow код:
User-agent: *
Disallow: /Що відбувається в цьому коді:
- Зірочка * поруч з User-agent означає «всі користувацькі агенти». Зірочка — це символ підстановки, що означає, що правило застосовується до кожного User-agent.
- Коса риска / поруч з Disallow означає, що ви хочете заборонити доступ до всіх сторінок, які містять «yourdomain.com/», тобто до кожної сторінки вашого сайту.
Як використовувати файл robots.txt, щоб заблокувати доступ одного бота до вашого сайту
Давайте змінимо ситуацію. У цьому прикладі ми уявимо, що вам не подобається, що Bing сканує ваші сторінки. Ви фанат команди Google і не хочете, щоб Bing навіть заглядав на ваш сайт. Щоб заборонити сканування вашого сайту тільки Bing, вам потрібно замінити символ підстановки * на Bingbot:
User-agent: Bingbot
Disallow: /Тепер у наведеному вище коді йдеться про застосування правила «Disallow» лише до ботів з User-agent «Bingbot».
Навряд чи на практиці ви захочете заблокувати доступ до Bing, але цей сценарій може стати в пригоді, якщо є певний бот, якому ви не хочете дозволяти доступ до вашого сайту. На сайті UserAgentString.com є хороший список відомих імен User-agent більшості сервісів.
Як використовувати robots.txt для блокування доступу до певної папки або файлу
Для цього прикладу припустимо, що ви хочете заблокувати доступ лише до певного файлу або папки (і всіх підпапок цієї папки). Щоб застосувати це до WordPress, скажімо, ви хочете заблокувати:
- всю папку wp-admin;
- файл wp-login.php.
Ви можете скористатися наступними командами:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-login.phpВказуйте правила з урахуванням регістру. Наприклад, правило:
User-agent: *
Disallow: /file.asp
поширюється на URL https://www.example.com/file.asp, але не на https://www.example.com/FILE.asp.
Як використовувати файл robots.txt, щоб надати роботам повний доступ до вашого сайту
Якщо у вас немає причин блокувати доступ роботів до будь-яких сторінок вашого сайту, ви можете додати наступну команду:
User-agent: *
Allow: /Або альтернативно:
User-agent: *
Disallow:Як за допомогою robots.txt дозволити доступ до певного файлу в забороненій теці
Тепер припустимо, що ви хочете заблокувати цілу папку, але хочете дозволити доступ до певного файлу в цій папці. Ось де в пригоді стане команда Allow. І вона насправді дуже застосовна до WordPress. Віртуальний стандартний файл WordPress robots.txt чудово ілюструє цей приклад:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpЦей фрагмент блокує доступ до всієї папки /wp-admin/ за винятком файлу /wp-admin/admin-ajax.php.
Як використовувати robots.txt, щоб заборонити ботам сканувати результати пошуку в WordPress
Одне з специфічних для WordPress налаштувань, яке ви можете зробити, — це заборонити пошуковим роботам сканувати сторінки результатів пошуку. За замовчуванням WordPress використовує параметр запиту «?s=».
Тому, щоб заблокувати доступ, все, що вам потрібно зробити, це додати наступне правило:
User-agent: *
Disallow: /?s=
Disallow: /search/Це може бути ефективним способом зупинити «м’які» помилки 404 , якщо ви їх отримуєте.
🔗 10 найкращих плагінів WordPress для пошуку на сайті
Як створити різні правила для різних ботів у файлі robots.txt
До цього моменту всі приклади стосувалися одного правила за раз. Але бувають ситуації, коли треба застосувати різні правила для різних ботів. Тоді потрібно просто додати кожен набір правил під відповідним User-agent для кожного бота.
Наприклад, якщо ви хочете створити одне правило, яке застосовується до всіх ботів, і інше правило, яке застосовується тільки до Bingbot, ви можете зробити це таким чином:
User-agent: *
Disallow: /wp-admin/
User-agent: Bingbot
Disallow: /У цьому прикладі всім ботам буде заблоковано доступ до /wp-admin/, але Bingbot буде заблоковано доступ до всього вашого сайту.
При купівлі на рік — знижка 20%
Як перевірити файл robots.txt
Якщо robots.txt створений неправильно:
- Деякі сторінки, які ви не хочете показувати у пошукових системах, можуть все одно відображатися в результатах пошуку.
- Або навпаки, важливі сторінки вашого сайту можуть бути заблоковані для пошукових систем, що може знизити кількість відвідувачів.
- Новий контент може не з’являтися у пошукових системах чи з’являтися з великою затримкою.
- Це може призвести до меншого трафіку на сайті та погіршення його рейтингу в пошукових системах.
Тож щоб переконатися, що ваш файл robots.txt налаштований правильно та працює належним чином, слід ретельно його протестувати.
Google Search Console
В Google Search Console є звіт robots.txt. Це простий у використанні інструмент, який виявляє потенційні проблеми у вашому файлі robots.txt.
Просто перейдіть до інструменту та виберіть ресурс, який хочете перевірити. Також ви можете перейти в цей звіт прямо з Google Search Console → розділ Налаштування → Відкрити звіт навпроти robots.txt.
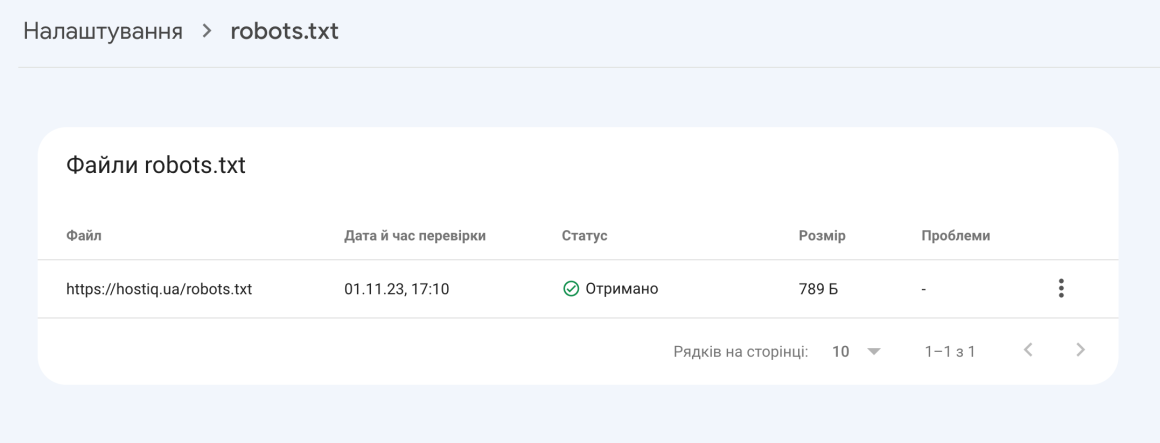
Звіт robots.txt показує, які файли robots.txt Google знайшов для вашого сайту, дату останнього сканування, а також будь-які попередження або помилки, що виникли. У звіті також можна подати запит на повторне сканування файлу robots.txt в екстрених ситуаціях: наприклад, коли ви оновили файл важливими правилами та хочете, щоб Google якомога скоріше про них дізнався.
Стаття з теми:

Logeix
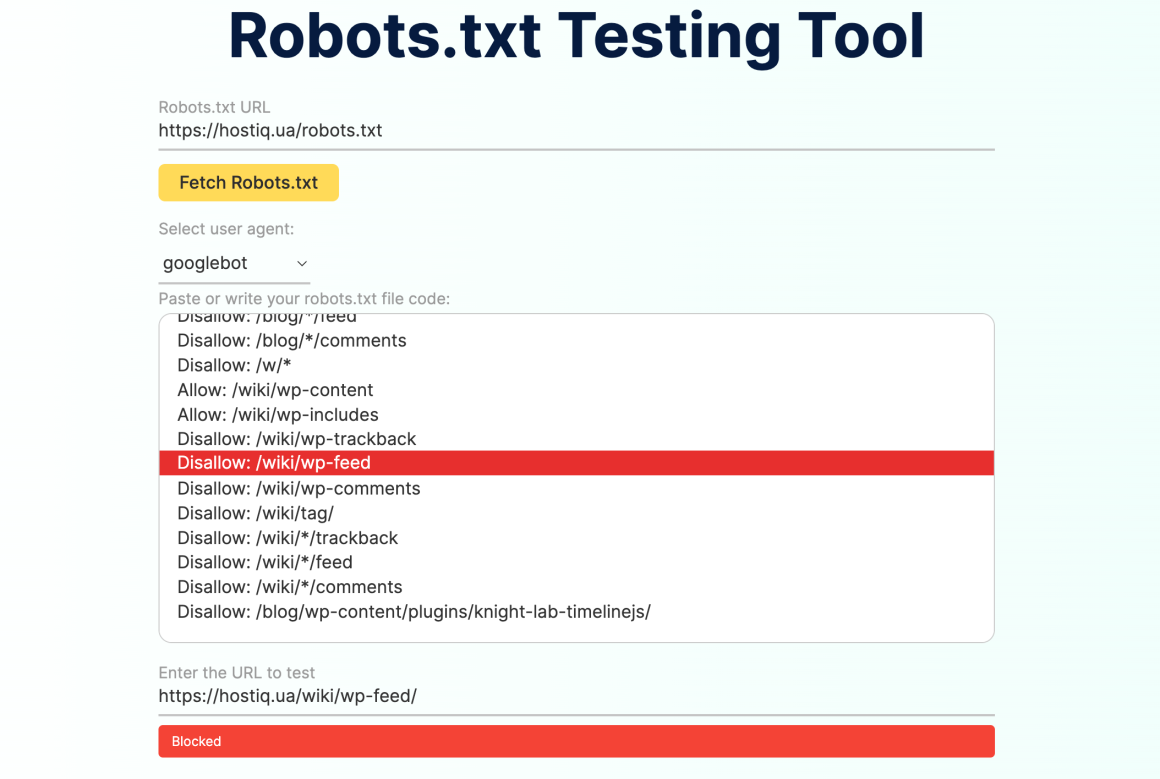
Також для перевірки robots.txt можна використовувати зручні сторонні сервіси на кшталт Logeix.
Введіть URL-адресу robots.txt сайту, який хочете перевірити, або просто вставте код файлу robots.txt. В рядку «Select user agent» можна вибрати, від якого User-Agent ви хочете запустити тест. Після цього введіть адресу сторінки, яку ви хочете перевірити, і інструмент повідомить, чи доступна вона для сканування, чи заблокована robots.txt.
Якщо сторінка доступна для сканування, ви побачите зелену відповідь «Crawlable». Якщо правила файлу забороняють сканувати сторінку, ви отримаєте червоний напис «Blocked», а в полі вище сервіс підсвітить рядок з правилом, яке блокує сканування.
🔗 25 SEO-інструментів, які можуть вам стати в пригоді
Що ще треба знати про файл robots.txt
Два важливих моменти, які вам варто знати перед створенням свого robots.txt.
Остерігайтеся UTF-8 BOM
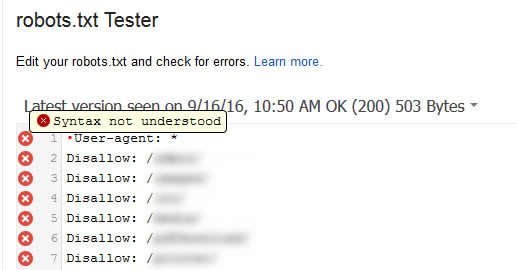
BOM розшифровується як byte-order mark, маркер порядку байтів. Це невидимий символ, який іноді додають до файлів старі текстові редактори. Якщо це трапиться з вашим файлом robots.txt, Google може прочитати його неправильно. Ось чому важливо перевіряти файл на наявність помилок.
Наприклад, як показано нижче, файл містив невидимий символ, і Google скаржився на те, що синтаксис не зрозумілий. В результаті така невидима штука робила рядки файлу robots.txt взагалі недійсними.
В статті Гленна Гейба ви можете прочитати детальніше, як UTF-8 Bom може вбити ваше SEO.
Googlebot здебільшого базується в США
Також важливо не блокувати Googlebot зі Сполучених Штатів, навіть якщо ви націлені на виключно на Україну. Іноді боти здійснюють локальний пошук, але Googlebot здебільшого базується в США.
📌 На завершення статті про robots.txt для сайту WordPress хочемо ще раз наголосити, що команда Disallow в цьому файлі не дорівнює тегу noindex. Robots.txt блокує сканування, але не обов’язково забороняє індексацію. Файл рекомендує пошуковим системам та іншим ботам, як вони мають взаємодіяти з вашим сайтом, але не контролює, чи буде ваш контент насправді індексований.
Більшості звичайних користувачів WordPress не потрібно змінювати стандартний файл robots.txt. Але якщо вам дошкуляє конкретний бот чи ви хочете обмежити взаємодію пошукових систем з певними сторінками, ви можете додати свої правила за допомогою SEO-плагінів, або вручну завантаживши файл robots.txt в кореневу папку вашого сайту.