
Веб-архів сайтів чи Web Archive — це сервіс, який збирає і зберігає копії сайтів. Це свого роду машина часу інтернету, яка дозволяє відстежити розвиток вебресурсу з початку його створення, переглянути вже неіснуючий сайт, а також відновити його навіть за відсутності резервної копії.
У цій статті ви знайдете огляд базових можливостей веб-архіву сайтів і детальні інструкції з використання сервісу.
Архів інтернету — це некомерційна бібліотека книг, програмного забезпечення, сайтів, аудіо- і відеозаписів. Найбільш популярний проєкт — Wayback Machine, також відомий як веб-архів сайтів.
Це безкоштовний сервіс, де зібрані архівні копії вебресурсів за різні дати. Копії з’являються при збереженні вручну, а також коли вебкраулери відвідують сайт.
Вебкраулер, він же павук або бот — це програма, яка відвідує сайти, оцінює вміст, а потім переносить їх в базу пошукових систем або веб-архіву, як в нашому випадку.
За допомогою інтернет-архіву можна дізнатися, як виглядав сайт раніше: місяць або кілька років тому.

Саме це і було початковою метою проєкту. Однак за останній час функцій у машини часу сайтів стало більше.
Веб-архів сайтів використовують, щоб:
- переглянути, як сайт виглядав раніше;
- відновити сайт, навіть якщо у вас немає резервної копії;
- проаналізувати зміни ресурсу за певний період;
- знайти унікальну інформацію, яку видалили;
- перевірити репутацію доменного імені перед реєстрацією — якщо раніше його використовували для розміщення сумнівного контенту, можуть виникнути труднощі і зараз.
Стаття з теми:

Як користуватися веб-архівом
Інтерфейс веб-архіву сайтів інтуїтивний у використанні.
Перейдіть на сторінку машини часу сайтів, вкажіть URL-адресу та натисніть «BROWSE HISTORY»:
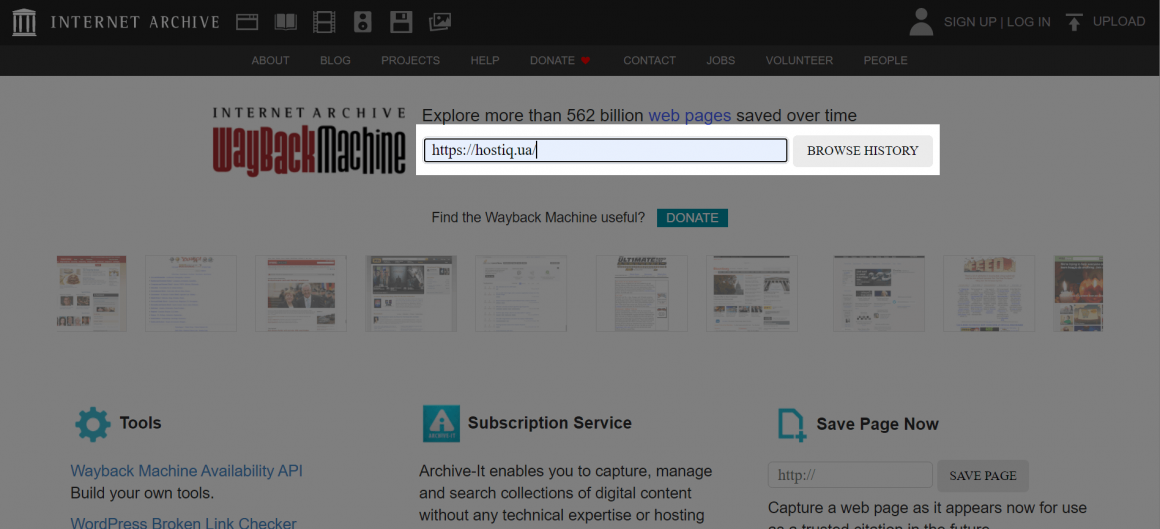
За замовчуванням веб-архів підвантажує секцію «Calendar», де можна подивитися старі версії потрібного сайту:
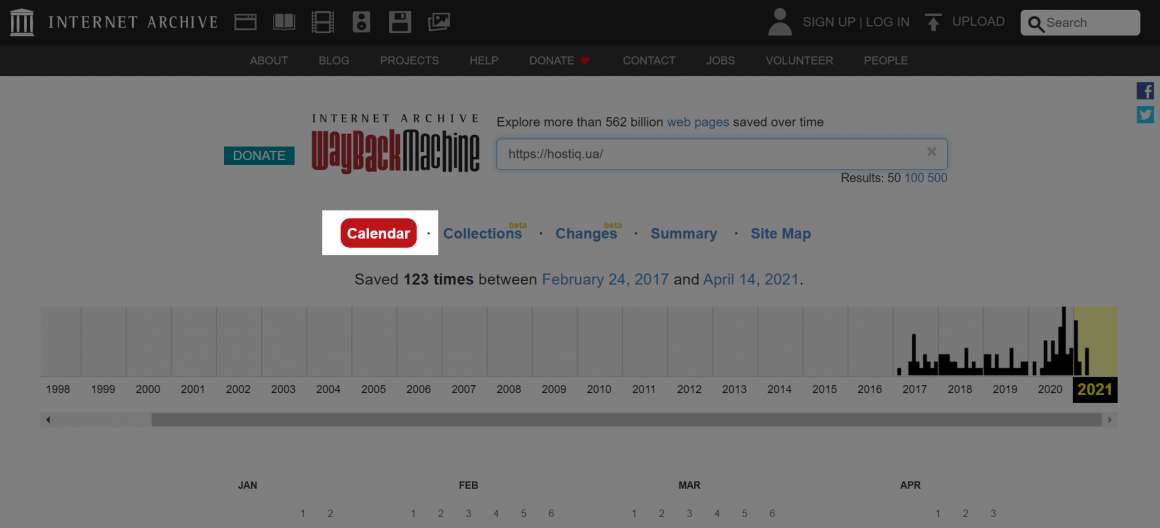
Після обробки запиту ви відразу ж побачите загальну інформацію про вебсторінку: кількість згенерованих архівів і шкалу часу, починаючи з першої копії до теперішнього часу:
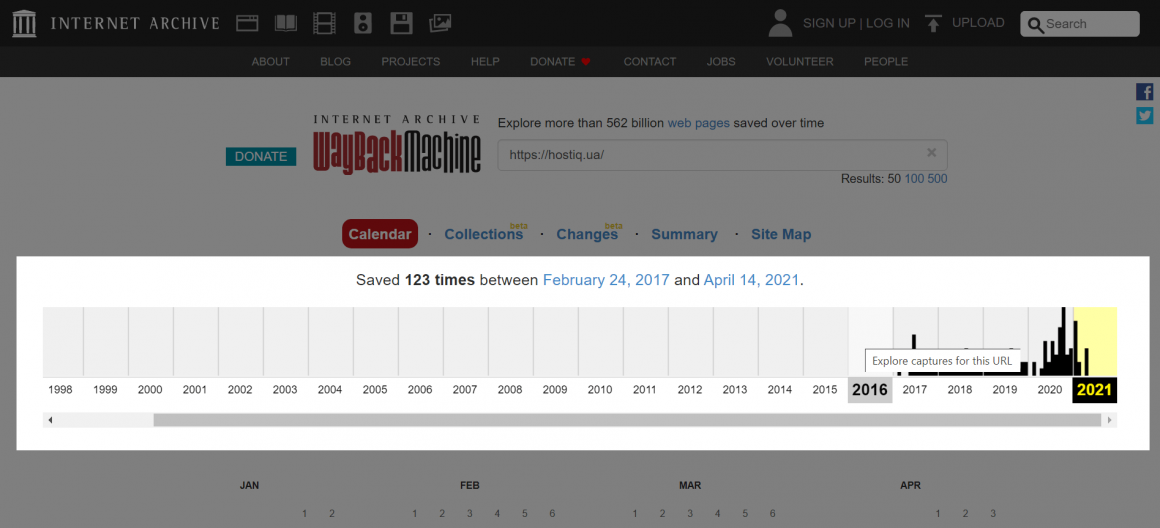
Виберіть рік на шкалі часу. Нижче ви побачите календар, де кольоровими маркерами позначені дати, коли вебкраулери інтернет-архіву сканували сторінку:
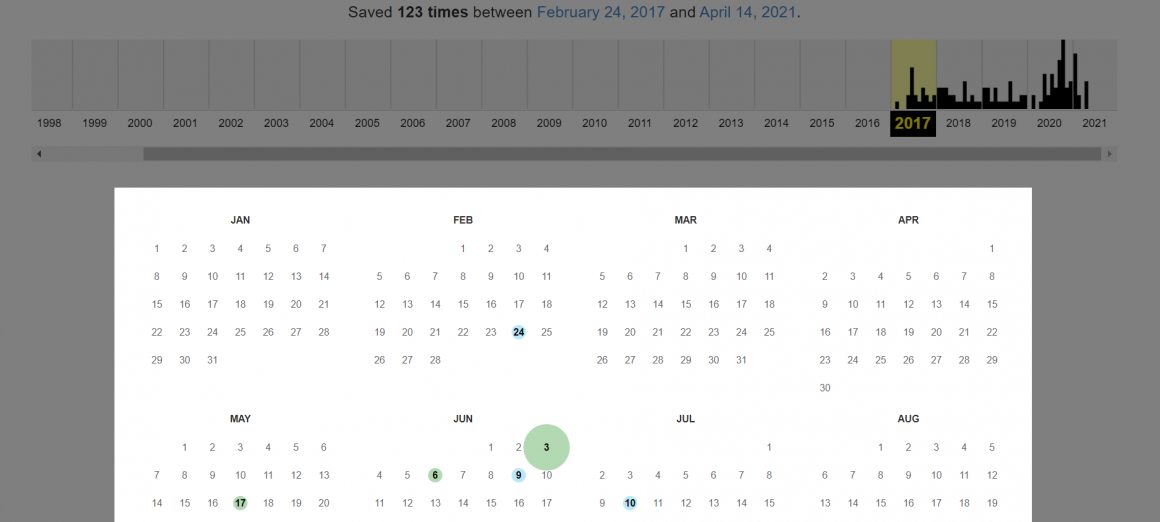
Маркери відзначені одним з чотирьох кольорів:
- Синій означає, що вебкраулер отримав у відповідь код зі статусом 200 OK, тобто сайт стабільно працював.
- Зелений відповідає коду 3хх — у момент створення копії на сайті був налаштований редирект.
- Помаранчевий і червоний кольори означають, що вебресурс був недоступний, і вебкраулер отримав код помилки 4хх чи 5хх.
Діаметр кола залежить від кількості звернень робота веб-архіву на сторінку в цей день. Чим більше коло, тим більше копій за цей день створив вебкраулер.
Спробуйте хостинг з купою принад: автовстановлювачем 330 движків, конструктором сайтів та теплою підтримкою 24/7!

Вибравши дату, наведіть курсор на неї і натисніть на час збереження:
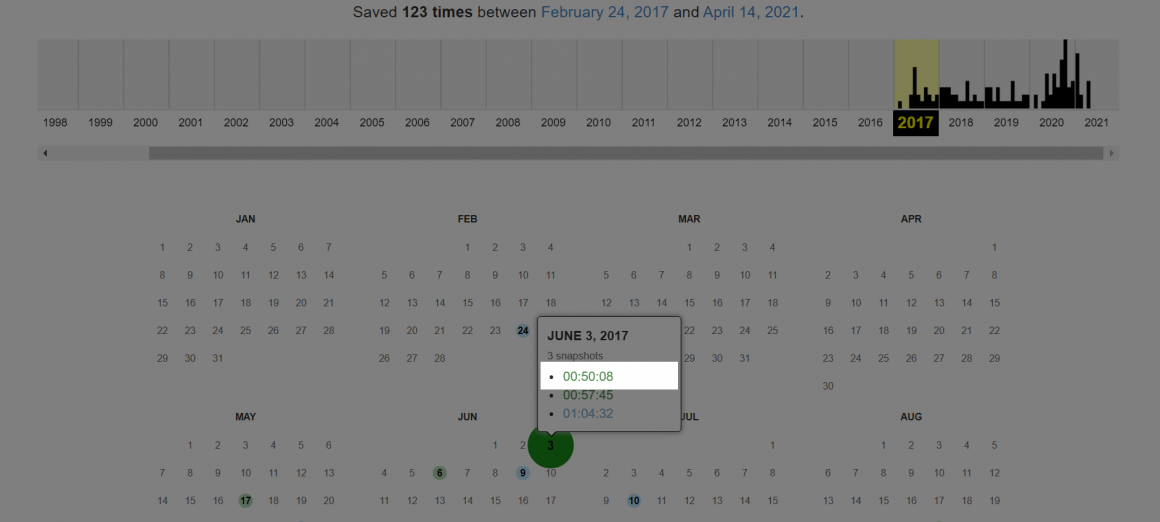
Ви побачите бажану версію вебсторінки.
Бувають ситуації, коли в інтернет-архіві немає старих версій ресурсу: правовласник зажадав видалити свій контент або сайт закритий через порушення закону про захист інтелектуальної власності. Додатково, на сайті можуть бути налаштування, які обмежують роботу вебкраулерів. Таким чином, боти його не сканують.
Іноді потрібний ресурс доступний, але в копії немає картинок або частини контенту. Це відбувається, якщо сайт був не в повному обсязі заархівований Wayback Machine. У такому випадку спробуйте відкрити версію сайту за інший день.
Додаткову інформацію про сайт можна знайти в секціях «Summary» і «Site Map»:
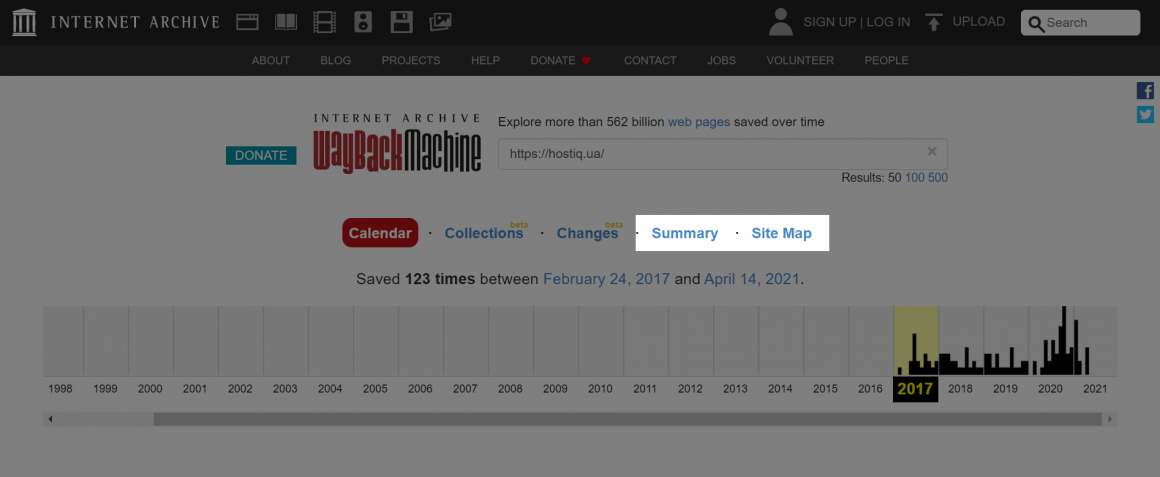
У секції «Summary» зібрана статистика по типу файлів, наприклад HTML, CSS, PNG, на вашому сайті.
Функціонал секції «Site Map» групує всі архіви потрібного ресурсу за роками, а потім будує візуальну карту сайту — радіальну діаграму. Центральне коло — це «корінь» сайту, його головна сторінка. Наступні кільця — інші сторінки. При наведенні курсора на кільця і осередки зверніть увагу, що URL-адреси вгорі змінюються. Ви можете вибрати сторінку, щоб перейти до архіву цієї URL-адреси.
Щоб виявити і відобразити зміни у вмісті архівів, використовуйте секцію «Changes»:
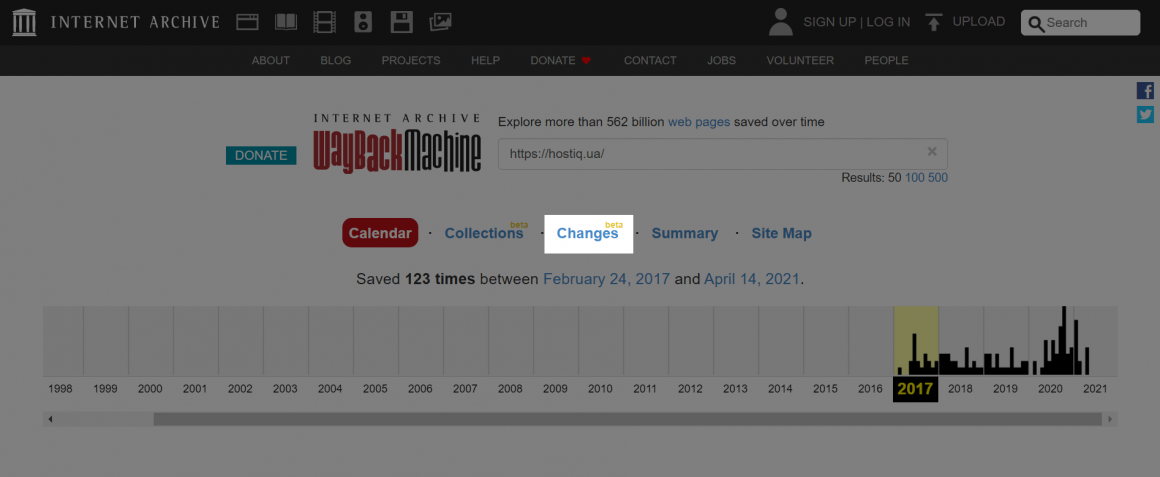
Виберіть дві дати і натисніть кнопку «Compare»:
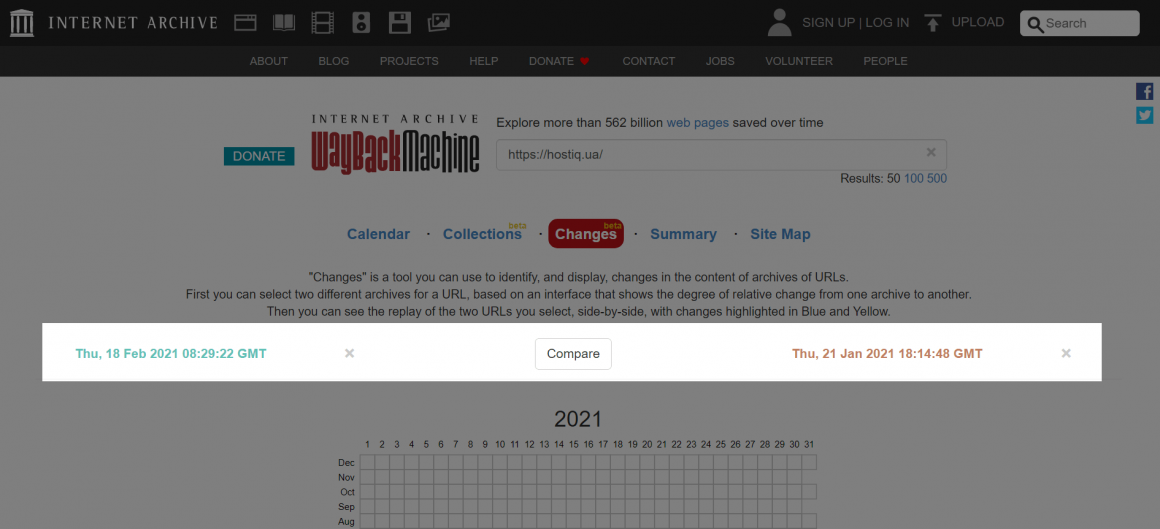
На новій сторінці з’являться дві версії сайту. Віддалений контент забарвлений в жовтий колір. Синій вказує на додавання вмісту.
Як зберегти поточну версію сайту у веб-архіві
Копії сайтів потрапляють у веб-архів завдяки вебкраулерам, які їх сканують. Однак це не єдиний спосіб. Просканувати сайт можна самостійно.
Щоб створити копію однієї URL-адреси, знайдіть опцію «Save page now» на головній сторінці Wayback Machine, введіть посилання і натисніть «Save page»:
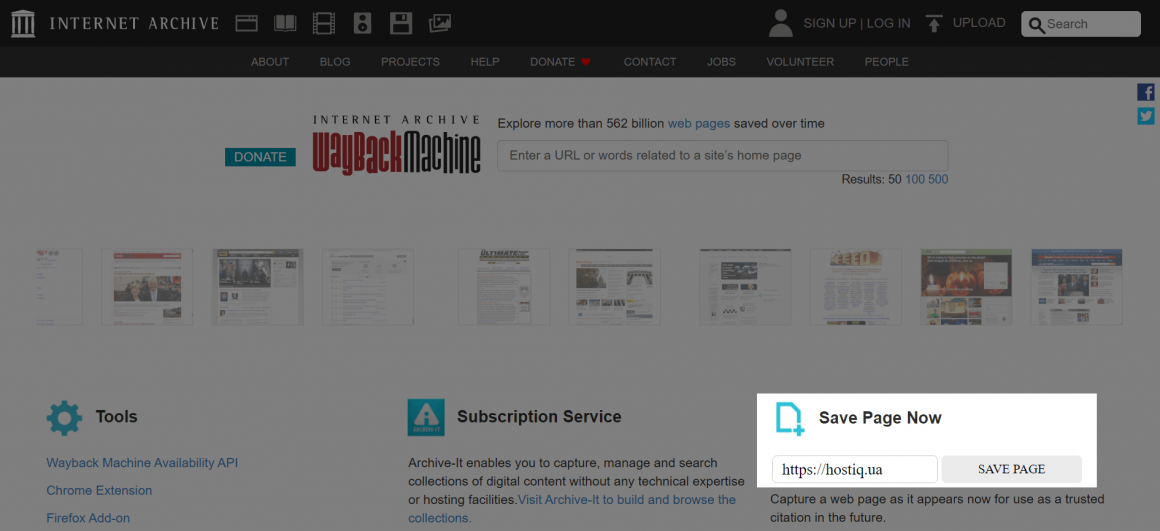
Таким чином, у веб-архів сайтів додасться поточна версія заданої URL-адреси.
Повторюйте цю дію перед важливими змінами на сайті та після них. У разі поломки або втрати даних ви завжди зможете відновити сайт через веб-архів.
Створювати копію всього сайту посторінково занадто багато роботи. Інтернет-архів надає платний сервіс, який архівує сайт в кілька кліків — Archive It.
Стаття з теми:

Як заборонити додавання сайту у веб-архів
Забороніть додавання вебресурсу в Wayback Machine, якщо ви:
- дорожите унікальністю контенту і не хочете, щоб його використовували навіть після видалення сайту;
- плануєте продати доменне ім’я і не хочете, щоб ваш контент асоціювався з новим власником;
- хочете видалити особисту інформацію з відкритого доступу.
Заборонити додавання сайту в архів інтернету можна двома способами:
- звернутися до підтримки веб-архіву;
- використовувати файл robots.txt.
Якщо ви звернетеся в підтримку, всю існуючу інформацію про сайт буде вилучено з архіву інтернету. Додатково, вебкраулери не будуть сканувати сайт в майбутньому.
Щоб запросити повне видалення вашого сайту з веб-архіву, напишіть на адресу info@archive.org, вказавши доменне ім’я в тексті повідомлення.
Файл robots.txt дозволяє лише заблокувати доступ для вебкраулерів. Після цього вони не будуть сканувати сайт, і інформація про нього не потрапить в архів інтернету. Але весь попередній матеріал буде доступний в Wayback Machine. Тобто користувачі зможуть подивитися, як сайт виглядав раніше.
Для заборони доступу додайте в файл robots.txt директиву:
User-agent: ia_archiver
Disallow: /
User-agent: ia_archiver-web.archive.org
Disallow: /
Важливо, щоб файл robots.txt був в кореневому каталозі для вашого домену.
Також вебкраулери не відвідують сайти, які захищені паролем.
Як відновити сайт з веб-архіву
Якщо сайт був загублений або зламаний, а резервної копії немає, спробуйте відновити контент з Wayback Machine. Ось кілька варіантів, як це можна зробити:
- скопіювати контент вручну;
- скопіювати контент за допомогою скрипта;
- звернутися до сторонніх служб.
Перший спосіб краще використовувати, якщо вам потрібна копія лише однієї або декількох сторінок. Другий і третій підійде тим, хто хоче скопіювати контент всього сайту.
Останні два варіанти — це використання сторонніх інструментів. Ми чули про ці скрипти та сервіси хороші відгуки, але не можемо гарантувати якість їх роботи. Радимо завжди створювати резервну копію вручну через панель управління хостингом або використовувати хостинг з автоматичними бекапами.
Спробуйте швидкий хостинг на чистих SSD-дисках з автоматичними бекапами!
Наша тепла підтримка на зв’язку 24/7

Скопіюйте контент вручну
У веб-архіву сайтів немає послуг зі зберігання резервних копій і відновлення роботи вебресурсів. Тому вбудованого функціоналу, який дозволить в кілька кліків отримати архів всього сайту, немає. Однак ви можете вручну скопіювати текст і код сторінок, а також зберегти картинки.
Щоб скопіювати код сторінки, перейдіть на неї в Wayback Machine, клікніть правою кнопкою миші та виберіть «View page source». Скопіюйте код і вставте його в текстовий редактор, де ви можете зберегти його як HTML-файл.
Скопіюйте контент за допомогою скрипта
Відновлення кожної окремої HTML-сторінки проєкту дуже трудомістке, тому ви можете використовувати спеціальні скрипти. Вони дозволяють отримати весь вміст сайту за один раз.
Деякі з найбільш популярних варіантів:
Зверніться до сторонніх служб
Існує безліч сторонніх служб, які допомагають з відновленням сайту з веб-архіву. Ціни за послуги будуть відрізнятися в залежності від обсягу сайту.
Однак більшість служб дають протестувати їх роботу безкоштовно.
Кілька служб, які можуть допомогти з відновленням сайту:
Що запам’ятати про веб-архів
- Інтернет-архів сайтів — безкоштовний проєкт, мета якого зберегти весь розміщений в інтернеті контент.
- Найбільш популярний інструмент проєкту — Wayback Machine. Це своєрідна машина часу, яка дозволяє подивитися, як сайт виглядав раніше.
- Веб-архів корисний для аналізу сайтів, відстеження змін і складання статистики, перевірки доменів перед покупкою.
- Веб-архів — це запасний варіант для відновлення сайту за відсутності резервної копії.
Обирайте надійний хостинг з розумною підтримкою 24/7!






