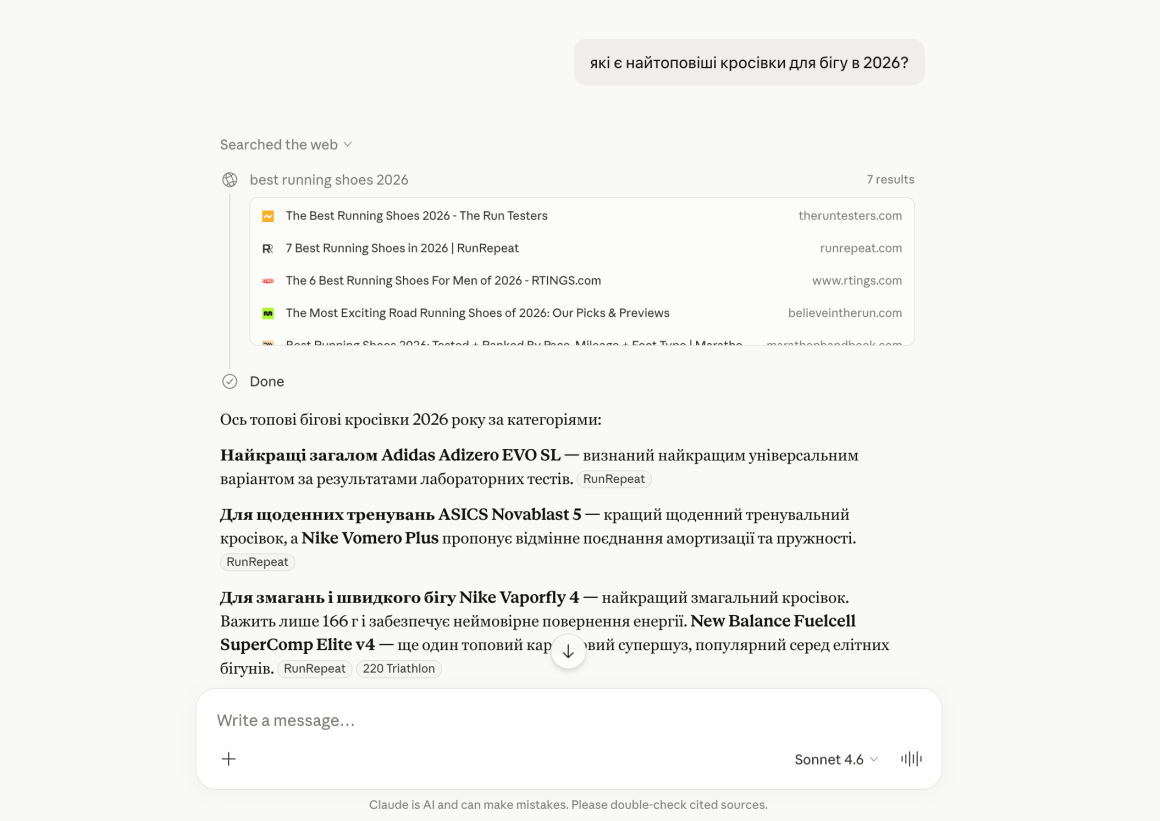
ШІ перехоплює увагу вашого потенційного клієнта вже на моменті пошукового запиту.
Крім того, все більше людей використовують замість гуглу ШІ: ChatGPT, Gemini та інші. У результаті користувач часто отримує готову відповідь без переходу на сайти.
Саме тому бізнесу вже недостатньо просто бути в топі Google — важливо, щоб ваш бренд і контент були помітними для ШІ. Про те, як це зробити — розповідаємо в нашій статті.

Що таке LLM SEO, GEO, AEO
Почнемо з невеликого словника, аби ми були на одній хвилі.
🔎 SEO, Search Engine Optimization — це класична оптимізація під пошукові алгоритми, щоб ваш сайт був першим у списку посилань Google чи іншого пошуковика.
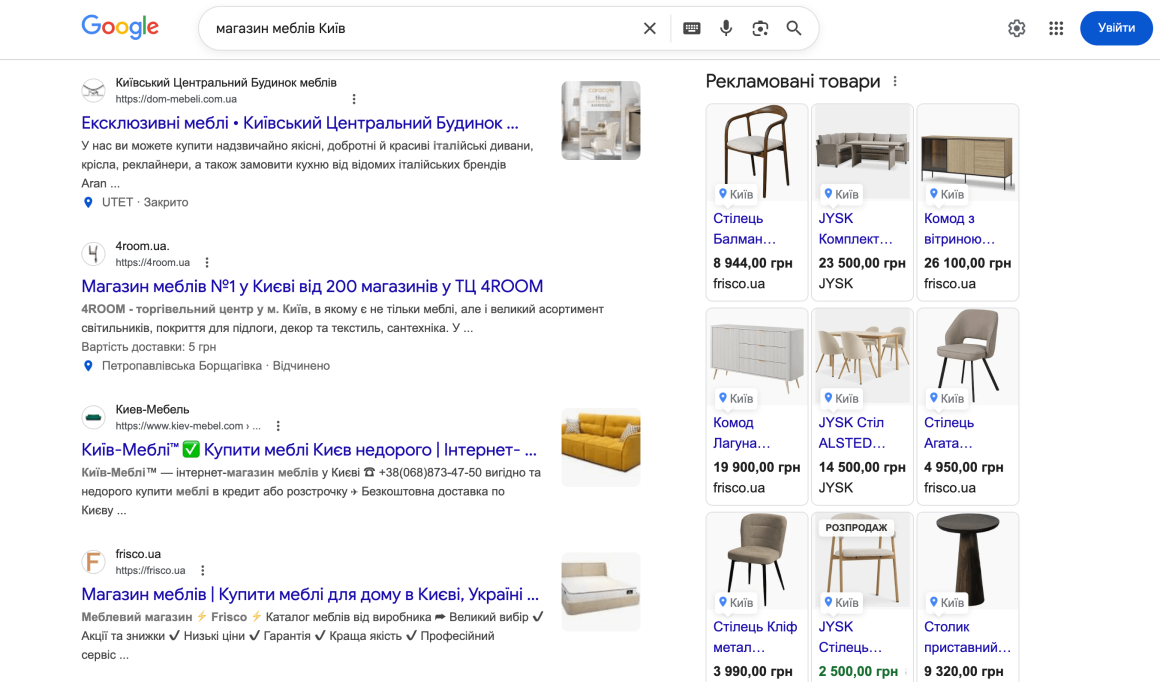
🔎 AEO, Answer Engine Optimization — оптимізація контенту під швидкі відповіді, щоб він ставав єдиною лаконічною відповіддю на прості питання для голосових помічників чи ШІ-блоків.
🔎 LLM SEO — це просування сайту під LLM, глобальні мовні моделі. Це оптимізація сторінок і контенту таким чином, щоб їх використовували й цитували ChatGPT, Gemini, Claude та інші мовні моделі.
🔎 GEO, Generative Engine Optimization — це вже конкретна практика для пошукових систем нового типу на основі штучного інтелекту, як-от Perplexity чи Google AI Overviews.
Межа між останніми двома поняттями дуже тонка. Вона полягає в тому, чи знає ШІ відповідь наперед. Якщо він бере відповідь зі своєї бази знань, на якій він навчався — вам потрібна оптимізація сайту під LLM. Якщо він шукає інформацію в реальному часі в інтернеті і на її основі генерує відповідь — це GEO. Але зараз більшість ШІ на базі LLM мають доступ до онлайн-даних, тож ці поняття можна використовувати взаємозамінно.
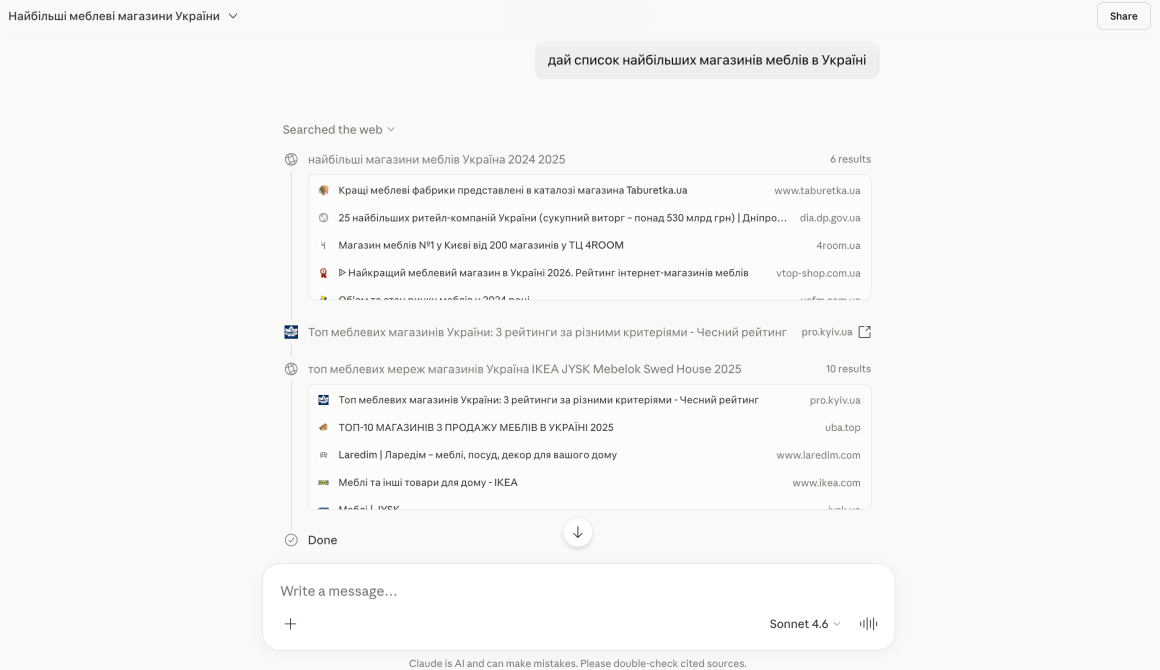
Чим LLM SEO відрізняється від класичного SEO
Після того, як розібралися з визначеннями, давайте заглибимося в те, чим просування під нейромережі відрізняється від пошукової оптимізації, тобто класичного SEO.
| Критерій | Класичне SEO | LLM SEO |
| Головна мета | Отримати позиції та кліки з пошукової видачі | Потрапити в AI-відповідь, цитату чи рекомендацію |
| Одиниця оптимізації | Сторінка та ключовий запит | Смисловий блок, відповідь, бренд |
| Як користувач бачить результат | Список посилань | Згенерована відповідь з джерелами чи без них |
| Що важливо | Індексація, релевантність, посилання, поведінка, контент | Зрозумілість, цитованість, структура, зовнішні згадки, консистентність |
| Роль бренду | Важлива, але часто вторинна | Дуже важлива: модель має розуміти, хто ви та з чим вас асоціювати |
| Метрики | Позиції, трафік, CTR, конверсії | Згадки, цитати, share of voice, позиція в списках, AI-referral |
Що варто запамʼятати з цієї таблиці:
🧱 ШІ мислить смисловими блоками, «шматками» інформації, а не сторінками. Якщо в класичному SEO сторінка і є одиницею контенту, то для LLM SEO важливо, щоб всередині тексту були чіткі, лаконічні блоки, які ШІ-модель може легко вирвати з контексту та цитувати. Це можуть бути питання-відповіді, списки чи ємні визначення в один абзац.
🧩 Консистентність бренду дуже важлива. Нейромережі звертають увагу на те, щоб інформація про ваш продукт всюди в інтернеті — на вашому сайті, в медіа чи у відгуках, збігалася. Як бути послідовним в цьому — поговоримо детальніше згодом.
Проте, мабуть, найважливіше, що ми хочемо сказати в цій статті: класичне SEO все одно залишається фундаментом для просування сайту.
По-перше, ШІ-пошук будується на основі традиційних пошукових систем. Більшість генеративних двигунів на кшталт Perplexity чи Google AI Overviews не шукають інформацію у вакуумі — вони звертаються до звичайних пошукових індексів, щоб знайти свіжі та релевантні сайти. Якщо ваш сайт не оптимізований технічно, погано індексується або не має авторитету в очах роботів Google — ШІ про нього просто не дізнається.
По-друге, частка ШІ-трафіку досі сильно поступається класичному пошуку. Традиційні пошукові системи все ще тримають левову частку ринку. Наприклад, Ahrefs в своєму дослідженні виявили, що Google приносить у 345 разів більше трафіку, ніж три основні ШІ системи разом узяті.
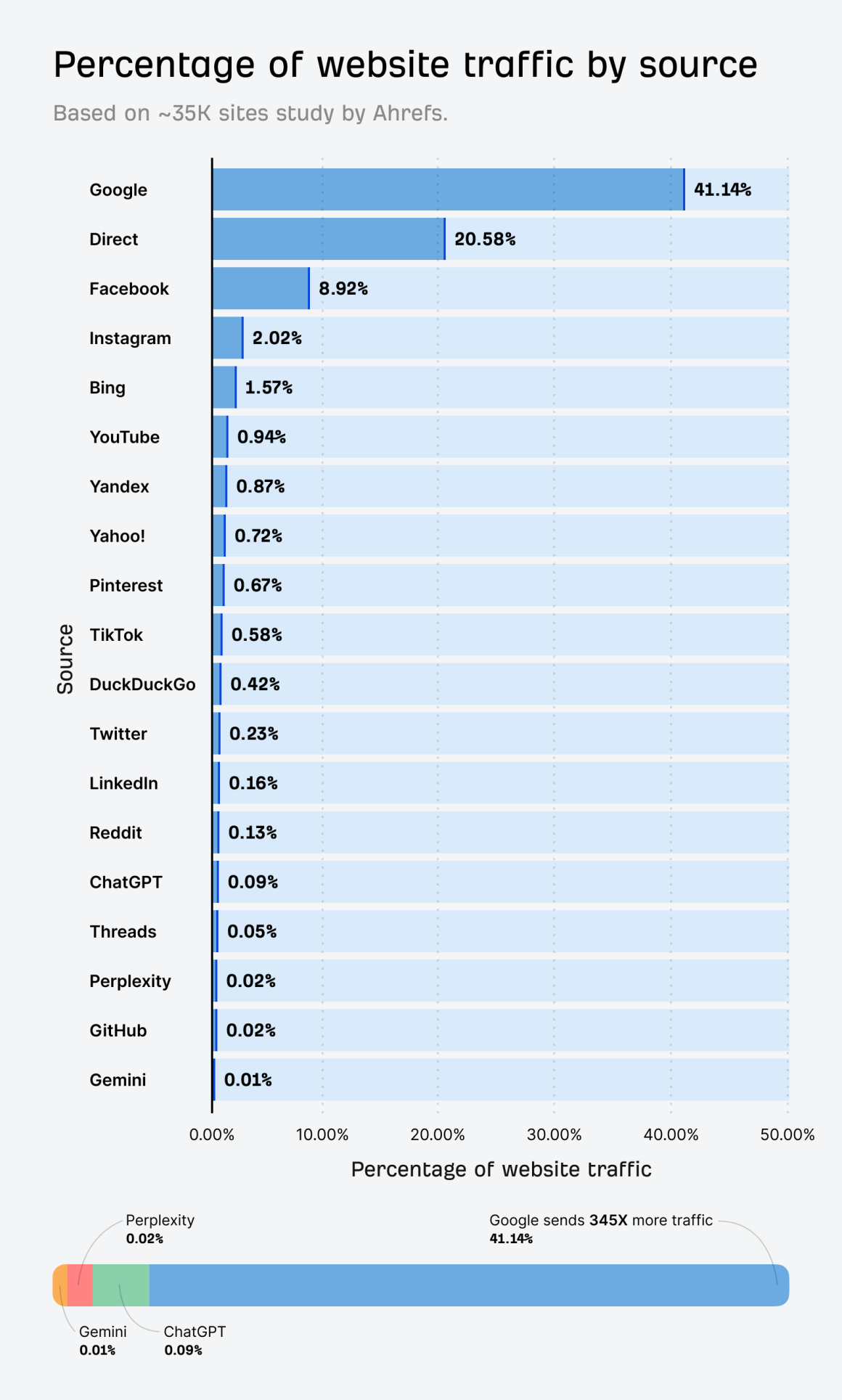
Тому просування сайту в ChatGPT чи інших ШІ — це не альтернатива класичному SEO, а наступний рівень онлайн-маркетингу. Ви просто не зможете провести якісну оптимізацію сайту під нейромережі, якщо до цього не було закладено міцний SEO-фундамент.
Звідки LLM бере інформацію про сайти та бренди
Щоб зрозуміти, як змусити нейромережу рекомендувати саме вас, треба розібратися, звідки вона взагалі знає про існування вашого бізнесу. Штучний інтелект використовує два абсолютно різних режими збору даних, і оптимізуватися потрібно під обидва.
Навчальні дані моделі
Це «базова пам’ять» нейромережі — колосальний масив інформації, на якому її навчали розробники. Сюди входять зліпки інтернету за минулі роки: мільярди онлайн-сторінок, книги, статті з медіа, Вікіпедія, форуми тощо.
Якщо ваш бренд був великим, часто згадуваним і авторитетним на момент навчання моделі, вона пам’ятатиме про вас за замовчуванням, навіть без доступу до інтернету.
Головний мінус: ця пам’ять статична. Якщо моделі востаннє «згодовували» дані в 2025 році, то про ваші оновлення, нові продукти чи зміну позиціонування у 2026 році вона з датасету нічого не дізнається.
Пошук у реальному часі
Коли користувач запитує щось свіже або специфічне, базової пам’яті моделі вже не вистачає. Тоді вмикається технологія RAG — Retrieval-Augmented Generation, генерація з використанням даних пошуку.
ШІ-пошуковик робить швидкий запит у традиційну пошукову систему на кшталт Google чи Bing, сканує перші 5–10 сайтів із видачі, нарізає їхній контент на шматки, аналізує та формує з них фінальну відповідь для користувача.
Головний плюс: це шанс для молодих або оновлених брендів потрапити в ШІ-відповіді. Навіть якщо вас не було в початковому датасеті, якісна оптимізація сайту та високі позиції в класичному пошуковику дозволять ШІ знайти вас через пошук у реальному часі.
Чому результати LLM можуть відрізнятися
Видача ШІ не має сталих позицій — вона завжди динамічна. Те, що ChatGPT хвалить ваш бренд, а Gemini чи Perplexity його ігнорують, залежить від трьох причин:
- Різні пошуковики для Live Search. ChatGPT Search використовує індекс Bing, Google AI Overviews спирається на власну базу, а Perplexity комбінує кілька джерел. Якщо вашого сайту немає в топі Bing, ChatGPT не знайде його в реальному часі.
- Різна вага джерел. Кожна модель має власні пріоритети: одна більше довіряє класичним медіа та галузевим блогам, інша — живим обговоренням на Reddit, Quora чи локальних форумах.
- Контекст і випадковість. Нейромережі враховують попередній діалог із користувачем та мають вбудований фактор випадковості. Тому один і той самий бот за однаковими запитами від двох різних людей видасть різні рекомендації.
Саме тому видимість бренду в нейромережах потрібно вимірювати не по одному запиту, а по набору промптів і динаміці повторюваних згадок. Про це детальніше поговоримо в наступних розділах.
Як LLM вибирає джерела, компанії або сайти
На противагу класичним пошуковикам, LLM не ранжує компанії за кількістю зворотних посилань чи щільністю ключових слів.
Натомість, коли ШІ обирає, яку саме компанію додати у відповідь, він звертає увагу на наступні фактори:
- Чіткий зв’язок бренда з категорією. ШІ має чітко розуміти вашу ідентичність. Якщо ви послідовно всюди згадуєтеся як «CRM для логістики», модель ймовірніше витягне вас під цей запит. Якщо зв’язок розмитий — вас проігнорують.
- Частота та контекст згадок. Має значення не просто кількість посилань, а те, що саме про вас пишуть, адже ШІ аналізує тональність контенту. Позитивний контекст в авторитетних оглядах дає бренду величезний поштовх.
- Довіра до джерел. Якщо про вашу компанію написано на DOU, TechCrunch або у Вікіпедії, для LLM це вагоміший аргумент, ніж сотня згадок на щойно створених ноунейм-сайтах. ШІ цитує тих, кому «довіряє».
- Свіжість інформації. Для динамічних ніш (технології, фінанси, медицина) ШІ завжди намагається надавати пріоритет новішим даним.
- Структура контенту. Моделям простіше витягувати дані з тексту, який має чітку ієрархію, таблиці, списки та готові смислові шматки.
- Наявність доказів і фактів. ШІ чудово розпізнає «воду» та пусті маркетингові гасла типу «ми найкраща компанія на ринку». Натомість моделі віддають перевагу конкретним цифрам, кейсам, технічним характеристикам.
- Відгуки та рейтинги. Коли користувач просить ШІ «порадити найкращих», модель перевіряє незалежні платформи з відгуками, сканує оцінки реальних людей, резюмує їх і на основі цього готує відповідь.
Тепер давайте розберемося, як підготувати контент для просування в AI пошуку.
Контент на сайті: як писати статті, які LLM може процитувати
Від теорії переходимо до практики — як створювати контент, який ШІ з більшою ймовірністю помітить.
Формуйте послідовну сутність бренду
Щоб ШІ чітко зв’язав назву вашої компанії з правильними асоціаціями, використовуйте формулу ідеальної сутності бренду:
Бренд + Категорія + Позиціонування + Ключова властивість + Сценарій використання + Доказ
| Компонент формули | Що це | Приклад |
| Бренд | Унікальна назва компанії, уніфіковане написання у всіх джерелах | Wascobags |
| Категорія | Чітка ринкова ніша або тип продукту | Рюкзаки для подорожей |
| Позиціонування | Стиль, ціновий сегмент або характер бренду | Бюджетні рюкзаки для ручної поклажі |
| Ключова властивість | Технічна фішка, матеріал або головна цінність | Ідеально підходять для лоукостерів |
| Сценарій використання | Конкретна життєва ситуація клієнта | Місткий рюкзак для подорожей лоукостерами, коли не хочеться платити за додатковий багаж |
| Доказ | Соціальний доказ, цифри, тести або нагороди | Розміри чітко відповідають вимогам авіакомпаній WizzAir, RyanAir |
Кожна сторінка сайту має в унісон повторювати цю сутність бренду.
Пишіть самодостатні смислові блоки
Оскільки ШІ мислить «шматками» інформації, а не сторінками, пишіть свій контент так, щоб робот міг легко вирвати будь-який абзац із контексту і процитувати його у своїй відповіді. Якщо думка надмірно розтягнута, або щоб зрозуміти її, треба обов’язково прочитати три попередні абзаци — ШІ просто проігнорує цей матеріал.
Ось головні правила, як створити самодостатній контент для AI-пошуку:
- Один абзац — одна закінчена думка. Пишіть ємні, лаконічні визначення за принципом «теза + аргумент + приклад». Кожен такий блок повинен мати сенс, навіть якщо читач не бачив решти статті.
- Використовуйте списки та маркування. Нейромережі часто беруть зі сторінки структуровані переліки, адже їх найпростіше трансформувати у фінальну відповідь.
- Впроваджуйте формат «Питання-Відповідь». Формулюйте підзаголовки або окремі блоки прямо у вигляді запитань, які люди ставлять чат-ботам, наприклад: «Як вибрати безпечне дитяче автокрісло?», і одразу під ними давайте пряму, чітку відповідь.

Головний маркер якості для LLM-тексту: якщо ви скопіюєте один випадковий абзац зі своєї статті та відправите його другу, він має повністю зрозуміти, про що йдеться, без додаткових пояснень. Саме такі «автономні» блоки ШІ забирає у свої відповіді найохочіше.
Використовуйте правильну структуру H1-H3
Класичну ієрархію заголовків (H1, H2, H3) у традиційному SEO використовують, щоб показати роботам Google вагу ключових слів та загальну тему сторінки. Для LLM SEO заголовки мають іншу роль — вони маркують наміри (інтенти) користувача та слугують для ШІ «дорожньою картою» під час нарізання тексту на смислові блоки:
- H1 — назва статті. Задає головну тему. ШІ одразу розуміє, у яку «папку» у своїй пам’яті віднести цю сторінку.
- H2 — основні блоки. Розбивають глобальну тему на великі логічні кроки або підтеми.
- H3 — конкретні мікро-інтенти. Найважливіший рівень для ШІ. Саме сюди потрібно вписувати точкові запити, які люди зазвичай вбивають у ChatGPT чи Perplexity. Наприклад, замість сухого заголовка «Вибір іграшки для собаки» краще написати H3 «Як вибрати безпечну іграшку для цуцика до 6 місяців».
Правильна структура заголовків допомагає ШІ-моделі миттєво зорієнтуватися, а отже збільшує ваші шанси потрапити у відповіді ChatGPT чи іншого AI.
Розкривайте вієроподібні запити
Коли користувач ставить запитання, ШІ рідко шукає відповідь лише за цією однією фразою. Сучасні пошукові AI-системи використовують технологію Query Fan-Out — це декомпозиція або розгалуження запиту. Штучний інтелект бере лаконічний запит користувача і самостійно генерує на його основі 3–5 додаткових, більш специфічних і деталізованих пошукових запитів, щоб зібрати максимально повну картину.
Тому, коли ви пишете статтю на певну тему, не обмежуйтеся базовим ключовим словом. Завжди розгортайте інтент у глибину:
- Проаналізуйте супутні питання. Подумайте, які 4–5 уточнюючих запитань виникнуть у людини (і відповідно — у ШІ) після прочитання головної тези.
- Створюйте підзаголовки під ці питання. Прямо в межах однієї статті дайте короткі, вичерпні відповіді на всі ці розгалужені теми.
Ваше завдання — написати такий матеріал, щоб коли Query Fan-Out згенерує свої пʼять додаткових запитів, ШІ знайшов відповіді на кожен з них у різних абзацах вашої ж сторінки, і йому не довелося йти на сайти ваших конкурентів.
Форматуйте контент коректними HTML-тегами
Щоб полегшити роботу алгоритмам ШІ, структуруйте свій контент за допомогою HTML-тегів.
Ось елементи форматування, з яких чат-боти найохочіше забирають інформацію:
- Таблиці. Якщо ви порівнюєте ціни, характеристики товарів чи ліміти навантаження — оформлюйте це виключно таблицею.
- Списки з жирним виділенням. Ідеально для інструкцій. Починайте кожен пункт з конкретної дії, виділеної жирним: «1. Створіть вебхук. Для цього…». Так нейромережа одразу бачить суть кожного кроку.
- Формат «Термін — Значення». Якщо на сторінці є глосарій, часті питання або словник понять, використовуйте чітку структуру списків визначень: <dl>, <dt>, <dd>. Це допомагає ШІ безпомилково пов’язати термін із його описом.
- Змістовні посилання. ШІ оцінює лінки разом із текстом навколо них. Не використовуйте анкори на кшталт «тут» або «за посиланням». Пишіть змістовно: «читайте умови акції бренду» або «стаття про найкращі плагіни для WordPress». Це дає роботу розуміння, куди саме веде посилання.
- Маркування важливого. Виділяйте тегом <strong> ключові цифри, дедлайни чи головні фішки. Під час збору інформації ШІ насамперед звертає увагу на такі семантичні акценти в коді сторінки.
Ми думали, чи не додати цей пункт в наступний розділ про технічну оптимізацію, але HTML-розмітка давно стала своєрідною пунктуацією для авторів, тому лишимо це тут.
Технічна оптимізація сайту під LLM
Щоб робот витягнув із вашого сайту правильні відповіді, йому потрібно допомогти на рівні коду, тегів та серверної логіки.
Доступність сайту для ШІ-краулерів
Щоб ChatGPT, Gemini чи Perplexity процитували ваш сайт, їхні роботи мають спочатку туди потрапити. Будь-який технічний бар’єр на шляху краулера — це гарантована відсутність бренду у відповідях ШІ, оскільки моделі часто збирають дані в реальному часі.
Що треба налаштувати для доступу ШІ:
- Файл robots.txt. Переконайтеся, що сайт відкритий для головних ШІ-краулерів: GPTBot та ChatGPT-User, PerplexityBot, ClaudeBot, Google-Extended.
- Контроль noindex. Якщо сторінка закрита для Google, вона невидима і для ШІ.
- Динамічна sitemap.xml. Мапа сайту має вчасно оновлюватися та містити коректні теги дат (<lastmod>), щоб ШІ-павуки вчасно знаходили новий контент.
- Bing Webmaster Tools + Google Search Console. Bing є пошуковим рушієм для ChatGPT Search та Copilot. Якщо сайту немає в індексі Bing, ChatGPT не знайде його в реальному часі. Додавання sitemap.xml в обидва інструменти для вебмайстрів — обов’язкова умова.
Доступність контенту в HTML
Весь важливий контент має бути вшитий у сирий HTML-код сторінки одразу, а не генеруватися «на льоту».
Що ламає видимість для ШІ:
- Прихований контент. Текст, схований за кнопками «Показати більше» чи інтерактивними вкладками, які підвантажуються через JS лише після кліку мишкою.
- Попапи. Будь-яка інформація всередині спливаючих вікон, що активуються скролом чи часом на сторінці, закрита для роботів.
- Client-Side Rendering. Якщо ваш сайт збирає контент у браузері користувача за допомогою JavaScript, ШІ-боти дізнаються про нього останніми. На рендеринг таких сторінок йде забагато ресурсів, тому ШІ-краулери відкладають їх у довгу чергу. Щоб ваш контент ймовірніше потрапляв у видачу ШІ, використовуйте серверний рендеринг.
Спробуйте вимкнути JavaScript у браузері та перевірити сайт. Весь контент, який ви хочете бачити у відповідях ChatGPT, має залишатися повністю доступним для читання без додаткових кліків, розгортань чи попапів.
Навігаційне здоров’я сайту
ШІ-боти мають жорстко обмежений ліміт часу та ресурсів на сканування однієї сторінки. Якщо сайт повільно вантажиться або заплутує їх дублями контенту, вони йдуть далі, до конкурентів зі швидшими сторінками.
Критичні фактори навігаційного здоров’я:
- Швидкість завантаження. Якщо сервер довго відповідає, ШІ-краулер не чекатиме. Для SEO під LLM швидкість — це не просто фактор ранжування, це питання того, чи потрапите ви взагалі у відповідь.
🔗 Що впливає на швидкість завантаження сайту: відповідають фахівці з SEO та хостингу - Коректні теги canonical. ШІ дуже чутливий до дублювання контенту. Якщо на сайті немає чітких канонічних тегів (<link rel=”canonical” href=”…”>), модель може заплутатися, яку саме версію вважати першоджерелом. Правильний canonical гарантує, що ШІ забере до свого індексу потрібну сторінку та саме її поставить у фінальну цитату для користувача.
- Логічна внутрішня перелінковка. ШІ-агенти мандрують сайтом через контекстні посилання в тексті. Якісна перелінковка допомагає боту зв’язати різні статті та сторінки вашого бренду в один цілісний тематичний кластер. Коли ШІ бачить, що ваші матеріали посилаються один на одного за суміжними темами, він краще розуміє загальну експертизу сайту та може брати відповіді на розгалужені запити з ваших же сторінок.
Максимально полегшуйте вагу сторінок для роботів та зв’язуйте статті контекстними посиланнями. Чим простіший і швидший шлях ШІ-павука від однієї вашої тези до іншої, тим вища ймовірність, що саме ваш сайт стане його головним джерелом для відповіді на питання.
При купівлі на рік — знижка 20%
Мікророзмітка Schema.org
Мікророзмітка Schema.org захищає моделі від галюцинацій: замість того, щоб вгадувати за контекстом, де ціна товару, а де назва процесора, ШІ бере готові факти прямо з коду.
Які елементи розмітки варто використовувати:
- Product та Offer. Для карток товарів. Чітко вказуйте бренд, точну ціну, валюту, наявність і характеристики. ШІ-асистенти на кшталт ChatGPT зчитують ці теги, щоб миттєво порівняти ваш товар із конкурентами за запитом користувача.
- Organization та Brand. Створює цифровий профіль вашої компанії. Тут мають бути прописані офіційна назва, контакти, логотип та — найголовніше — поле sameAs із посиланнями на ваші профілі у Вікіпедії, LinkedIn та в авторитетних реєстрах.
- Author та Article. Пошукові алгоритми, особливо Google AI Overviews, уважно оцінюють експертність контенту. Розмітка автора сторінки із посиланням на його професійне портфоліо чи соцмережі підтверджує для ШІ, що текст писала жива людина з експертизою, а не генерував інший бот.
- FAQPage та Review. Питання-відповіді та рейтинги моделі зчитують в першу чергу, щоб сформувати блок рекомендацій у чаті.
Завдяки Schema.org ви говорите з ШІ його рідною мовою — мовою чистих структурованих даних, мінімізуючи ризик того, що модель «переплутає» ваші ціни чи характеристики з чужими.

llms.txt та ai.txt
Щоб контролювати доступ нейромереж до контенту, розробники створили два нові файли:
🔎 llms.txt — це експериментальний текстовий файл, який розміщують в корені сайту, щоб надати ШІ-моделям стислу, очищену від дизайну «карту» ресурсу. У ньому ви можете прямо підказати ШІ-інструментам найважливіші сторінки, ключові теми та матеріали вашого сайту, які варто вивчити в першу чергу.
🔎 ai.txt — ще один експериментальний файл, який намагається виконувати роль «етичного регулятора». Через нього власники сайтів пробують прописувати умови: яким саме ШІ-павукам дозволено збирати контент для навчання чи live-пошуку, а яким доступ закритий або обмежений.
На момент написання статті жоден із основних постачальників великих мовних моделей офіційно не впровадив llms.txt у свій протокол сканування:
- OpenAI (ChatGPT): дотримуються robots.txt, офіційно не використовують llms.txt.
- Anthropic (Claude): публікують власний файл llms.txt, але не повідомляли, що їх сканери використовують цей стандарт.
- Google (Gemini): використовують robots.txt (через User-agent: Google-Extended), нічого не згадують про підтримку llms.txt.
З файлом ai.txt ситуація ще скептичніша: OpenAI, Google, Anthropic його повністю ігнорують, їхні ШІ-боти дивляться виключно в robots.txt. Спроба створити окремий файл для ШІ провалилася, адже сучасні нейромережі все одно шукають інформацію через класичні пошуковики.
ШІ-оптимізація за межами сайту: як працювати із зовнішніми згадками та рейтингами
Великі мовні моделі не обмежуються скануванням вашого власного сайту. Навпаки, щоб сформувати неупереджену відповідь, ШІ шукає підтвердження вашої експертності на авторитетних сторонніх майданчиках. Тому щоб потрапити в AI відповіді, ви маєте активно працювати з зовнішнім інформаційним полем.
Які зовнішні джерела важливі для LLM-просування:
| Тип джерела | Чому важливе | Що оптимізувати |
| Рейтинги та агрегатори | Часто використовується в комерційних AI-відповідях | Місце в рейтингу, опис, актуальність, відгуки |
| Огляди та порівняння | Дають моделі готову структуру вибору | Згадка бренду поруч з конкурентами |
| Сайти з відгуками | Формують тональність відгуків про бренд | Рейтинг, свіжість відгуків, відповіді компанії |
| ЗМІ та PR | Посилюють авторитет | Єдине позиціонування, факти, цитати |
| Форуми, Reddit, Quora | Дають UGC і реальні сценарії використання | Натуральні обговорення, відповіді експертів |
| Каталоги | Посилюють сутність бренду | Єдиний нейминг, категорія, опис |
| YouTube, подкасти | Мультимодальні джерела та текстові розшифровки | Назва бренду, категорія, експертність |
Тепер розберемося з тим, як знайти конкретні джерела, які ШІ вважає авторитетними, та який контент для них писати.
Як працювати з рейтингами, оглядами та добірками
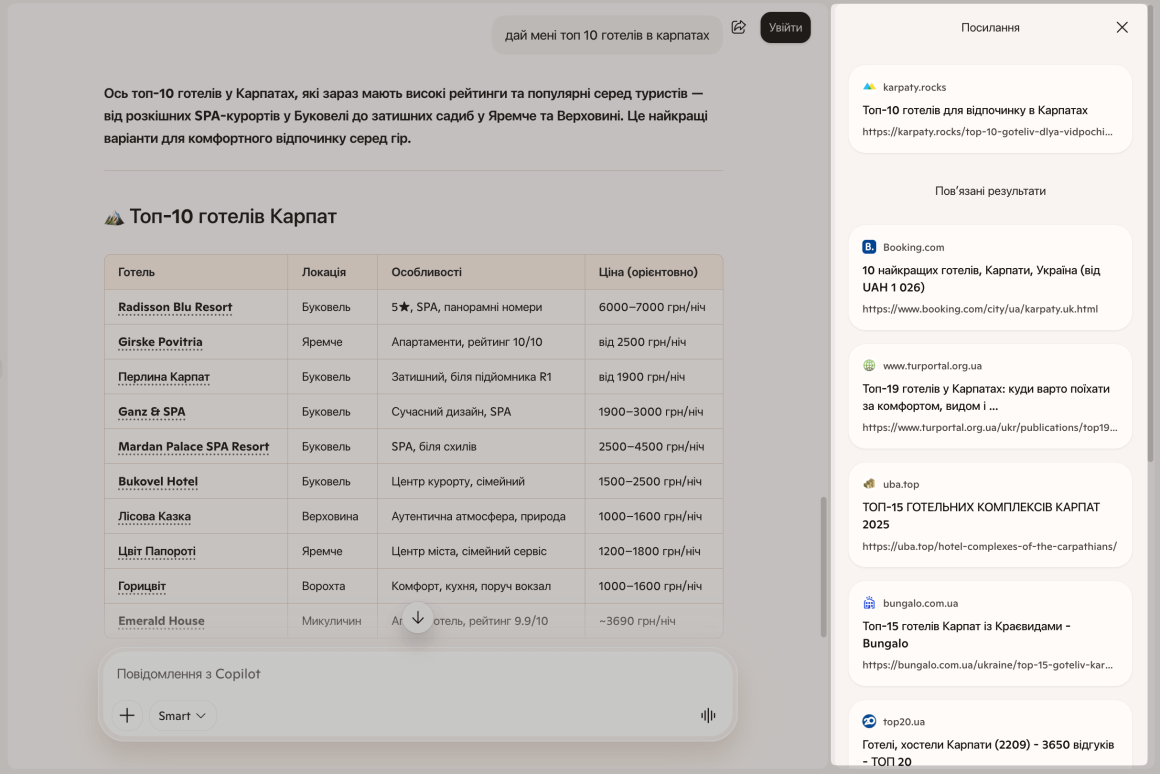
Коли користувач просить ШІ: «Порадь топ-5 найкращих CRM для малого бізнесу» або «Які бренди випускають якісне анатомічне взуття в Україні?», модель не формує відповідь «з голови». Вона миттєво сканує свіжі статті-добірки, незалежні платформи з відгуками та галузеві рейтинги. Ваша задача — бути присутніми на цих сторінках-донорах.
Алгоритм дій, щоб потрапити в ШІ-добірки:
- Знайдіть джерела вашого ШІ. Введіть у ChatGPT, Perplexity та Gemini ключові запити, за якими ви хочете ранжуватися. Подивіться, які саме сайти ці моделі відкривають і цитують у першу чергу.
- Постарайтеся потрапити в ці тематичні добірки. Зв’яжіться з редакціями цих знайдених сайтів-донорів. Ваша мета — домовитися додати ваш бренд в їхні актуальні статті-рейтинги. Якщо ШІ звик довіряти цій конкретній статті, поява вашого бренду в ній зробить вас кандидатом на цитування в чаті.
- Працюйте з незалежними платформами відгуків. Регулярно оновлюйте профілі та стимулюйте появу свіжих відгуків на майданчиках на кшталт Google Maps. ШІ аналізує тональність таких відгуків, щоб сформувати блок «Плюси та мінуси бренду за версією користувачів».
Як писати тексти для гостьових публікацій, щоб їх помічали LLM
Головне правило — ваші гостьові статті мають нести цінність для читача (і, відповідно, для ШІ). Пишіть експертні та корисні матеріали, наповнюйте їх унікальними даними, цифрами й кейсами з вашого власного досвіду, адже ШІ-моделі навчаються на якісних матеріалах і просто ігнорують низькопробні рерайти.
При цьому оформлюйте гостьові лонгріди за тими ж технічними правилами, що й свій ресурс: використовуйте чіткі HTML-заголовки <h2>-<h3>, марковані списки та порівняльні таблиці. Так ШІ-павуку буде максимально легко витягти й зафіксувати згадку вашого бренду.
Також не забувайте про послідовність позиціонування бренду:
Бренд + Категорія + Позиціонування + Ключова властивість + Сценарій використання + Доказ
Загалом, стаття для зовнішнього майданчика має бути такою ж якісною, як і для власного сайту.
Як відслідковувати ефективність просування під LLM
Стандартної «позиції в ChatGPT» не існує. Ефективність оцінюють в динаміці за групами промптів у кількох чат-ботах за допомогою таких метрик:
| KPI | Що показує | Як виміряти |
| Mention Rate | Частка згадок бренду серед усіх відповідей ШІ у вашій ніші | Автоматичний трекінг групи промптів через Ahrefs, SE Ranking або спеціалізовані GEO-сервіси |
| Top-3 Rate | Ймовірність того, що бренд потрапить у першу трійку рекомендацій чат-бота | Моніторинг видачі за комерційними промптами через API ШІ-моделей або парсери |
| Citation Rate | Як часто ШІ ставить клікабельне посилання на ваш сайт як на першоджерело | Аналіз блоків «Джерела» та цитат у Perplexity, Gemini та Google AI Overviews |
| Source Overlap | Співпадіння вашої бази посилань із сайтами, які ШІ найчастіше цитує за вашими ключовими темами | Порівняння списку топ-донорів з ШІ із вашими поточними зворотними посиланнями |
| Positioning Match | Наскільки тональність і контекст відповіді ШІ збігаються з позиціонуванням бренду | Семантичний аналіз відповідей чат-ботів: аналіз супутніх LSI-слів та асоціацій, які ШІ підбирає до бренду |
| AI-Referral Traffic | Кількість реальних користувачів, які перейшли на сайт за посиланнями з ШІ-відповідей | Google Analytics 4: звіт за переходами, відстеження джерел на кшталт ai.com, perplexity.ai тощо |
| Share of Voice (SOV) / Competitor Share | Ваша частка ринку всередині ШІ-видачі порівняно з головними конкурентами | Розрахунок співвідношення згадок вашого бренду до згадок конкурентів у межах однієї групи промптів |
Враховуйте, що збирати ШІ-статистику вручну неефективно через глибоку персоналізацію видачі: чат-боти підлаштовують відповіді під історію діалогів, локацію та профіль конкретного користувача. Ваша особиста видача завжди буде викривленою.
Щоб отримати об’єктивні дані, використовуйте сервіси на кшталт AI-модулів в Ahrefs чи SE Ranking. Вони надсилають сотні запитів через API у «чистих» сесіях без збереженого контексту та з різних IP-адрес, вираховуючи реальну середню ймовірність появи бренду у відповіді ШІ.
Чек-ліст: як просувати сайт під LLM
Наостанок ділимося чек-лістом, щоб ви могли швидко перевірити готовність сайту та контенту до вимог ШІ-пошуку:
- Технічний доступ. Сайт повністю відкритий у robots.txt для GPTBot, ChatGPT-User, PerplexityBot, ClaudeBot та Google-Extended.
- Індексація. Важливі сторінки не мають тегу noindex, а динамічна мапа sitemap.xml з коректними датами <lastmod> вчасно надходить у Google Search Console та Bing Webmaster Tools.
- Доступність контенту. Контент віддається ШІ в готовому вигляді з першої секунди, а не збирається потім у браузері користувача. Весь корисний текст, таблиці та списки вшиті в сирий HTML-код і не сховані за попапами, табами чи кнопками «Показати більше».
- Навігаційне здоров’я. Сторінки завантажуються миттєво, налаштовані чіткі теги canonical для захисту від дублів, а статті пов’язані щільною контекстною перелінковкою.
- ШІ-файли. В корінь сайту додано експериментальні Markdown-файли llms.txt та ai.txt як додаткова підказка для розробників та ШІ-агентів.
- Оптимізація контенту. Текст відповідає на конкретні питання користувача, містить чіткі інструкції, списки та FAQ. Інтегровано мікророзмітку Schema.org.
- Зовнішні згадки. Ваш бренд згадують у галузевих рейтингах, оглядах та добірках, які цитує ШІ.
- Консистентна сутність бренду. На власних ресурсах і у гостьових публікаціях ви постійно вживаєте одні і ті самі формулювання: Бренд + Категорія + Позиціонування + Ключова властивість + Сценарій + Доказ.
- Аналітика. Налаштовано автоматичний моніторинг згадок у ШІ: через сервіси Ahrefs або SE Ranking відстежується, як часто чат-боти рекомендують бренд, чи потрапляє він у топ-3 результатів і скільки реальних переходів на сайт це приносить.
На цьому все. Як ви могли зрозуміти зі статті, просування під ШІ — це не заміна класичному SEO, а потужна надбудова, яка об’єднує технічну оптимізацію, контент-маркетинг та управління репутацією бренду. ШІ-моделі не створюють інформацію з нуля, вони лише аналізують і узагальнюють уже наявний у мережі контент.
Щоб штучний інтелект рекомендував саме ваш бренд, він має регулярно бачити згадки про нього на авторитетних майданчиках, у структурованому вигляді та в правильному контексті. Тільки сильна та комплексна присутність бренду в інтернеті збільшує ваші шанси потрапити у відповіді ШІ.




